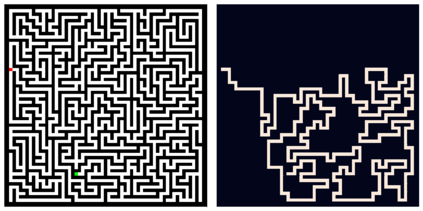
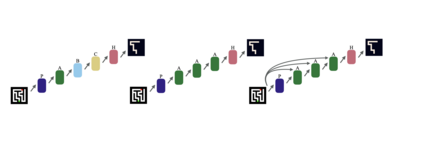
Machine learning systems perform well on pattern matching tasks, but their ability to perform algorithmic or logical reasoning is not well understood. One important reasoning capability is logical extrapolation, in which models trained only on small/simple reasoning problems can synthesize complex algorithms that scale up to large/complex problems at test time. Logical extrapolation can be achieved through recurrent systems, which can be iterated many times to solve difficult reasoning problems. We observe that this approach fails to scale to highly complex problems because behavior degenerates when many iterations are applied -- an issue we refer to as "overthinking." We propose a recall architecture that keeps an explicit copy of the problem instance in memory so that it cannot be forgotten. We also employ a progressive training routine that prevents the model from learning behaviors that are specific to iteration number and instead pushes it to learn behaviors that can be repeated indefinitely. These innovations prevent the overthinking problem, and enable recurrent systems to solve extremely hard logical extrapolation tasks, some requiring over 100K convolutional layers, without overthinking.
翻译:机器学习系统在模式匹配任务方面表现良好,但是它们执行算法或逻辑推理的能力并没有得到很好的理解。一个重要的推理能力是逻辑外推法,在逻辑外推法中,只对小型/简单推理问题进行训练的模型能够综合到在测试时达到大规模/复杂问题的复杂算法。逻辑外推法可以通过经常性系统实现,这些系统可以反复反复使用,解决困难推理问题。我们发现,这种方法无法触及高度复杂的问题,因为许多迭代应用时行为会退化,而我们称之为“过度思考”的问题。我们建议重新召回一个结构,在记忆中保留问题实例的清晰复制件,以免被遗忘。我们还采用渐进式培训程序,防止模型学习与迭代号有关的行为,而是推动它学习可以无限期重复的行为。这些创新可以防止过度思考问题,并使经常性系统能够解决极其困难的逻辑外推术任务,有些需要超过100K的演进层,而不会过度思考。