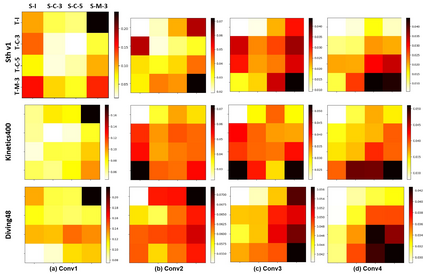
Video action recognition has been partially addressed by the CNNs stacking of fixed-size 3D kernels. However, these methods may under-perform for only capturing rigid spatial-temporal patterns in single-scale spaces, while neglecting the scale variances across different action primitives. To overcome this limitation, we propose to learn the optimal-scale kernels from the data. More specifically, an \textit{action perceptron synthesizer} is proposed to generate the kernels from a bag of fixed-size kernels that are interacted by dense routing paths. To guarantee the interaction richness and the information capacity of the paths, we design the novel \textit{optimized feature fusion layer}. This layer establishes a principled universal paradigm that suffices to cover most of the current feature fusion techniques (e.g., channel shuffling, and channel dropout) for the first time. By inserting the \textit{synthesizer}, our method can easily adapt the traditional 2D CNNs to the video understanding tasks such as action recognition with marginal additional computation cost. The proposed method is thoroughly evaluated over several challenging datasets (i.e., Somehting-to-Somthing, Kinetics and Diving48) that highly require temporal reasoning or appearance discriminating, achieving new state-of-the-art results. Particularly, our low-resolution model outperforms the recent strong baseline methods, i.e., TSM and GST, with less than 30\% of their computation cost.
翻译:CNN堆叠的固定尺寸 3D 内核部分解决了视频行动识别问题。 然而, 这些方法可能表现不足, 只能捕捉单一尺度空间的僵硬空间时空模式, 忽略不同行动原始体之间的比例差异。 为了克服这一限制, 我们提议从数据中学习最优规模的内核。 更具体地说, 提议从一组固定尺寸 3D 内核中生成一个固定尺寸内核的内核。 但是, 为了保证这些路径的交互性丰富和信息能力, 我们设计了新颖的 & textit{ 优化的特性聚合层 。 为了克服这个层次, 我们建议第一次从数据中学习最优规模的内核内核。 更具体地说, 我们的方法可以很容易地将传统的 2D CNN 改写到一些强的视频理解任务, 如行动识别, 边际的基底线, 快速的计算方法, 需要高层次的G- 时间推理学 。 提议的方法是彻底地评估, 高层次的计算,, 高层次推理学 30 。,, 和高层次的计算方法需要彻底地评估, 高层次的计算, 高层次推理学的计算, 。 。