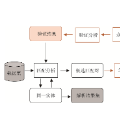
Entity resolution is essential for data integration, facilitating analytics and insights from complex systems. Multi-source and incremental entity resolution address the challenges of integrating diverse and dynamic data, which is common in real-world scenarios. A critical question is how to classify matches and non-matches among record pairs from new and existing data sources. Traditional threshold-based methods often yield lower quality than machine learning (ML) approaches, while incremental methods may lack stability depending on the order in which new data is integrated. Additionally, reusing training data and existing models for new data sources is unresolved for multi-source entity resolution. Even the approach of transfer learning does not consider the challenge of which source domain should be used to transfer model and training data information for a certain target domain. Naive strategies for training new models for each new linkage problem are inefficient. This work addresses these challenges and focuses on creating as well as managing models with a small labeling effort and the selection of suitable models for new data sources based on feature distributions. The results of our method StoRe demonstrate that our approach achieves comparable qualitative results. Regarding efficiency, StoRe outperforms both a multi-source active learning and a transfer learning approach, achieving efficiency improvements of up to 48 times faster than the active learning approach and by a factor of 163 compared to the transfer learning method.
翻译:暂无翻译