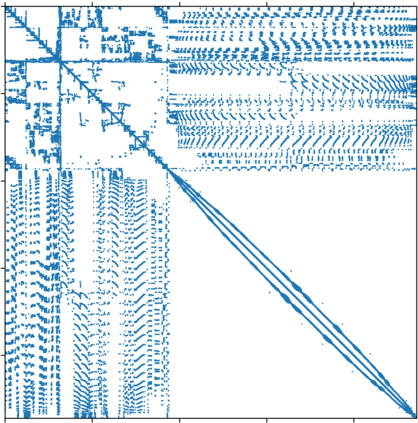
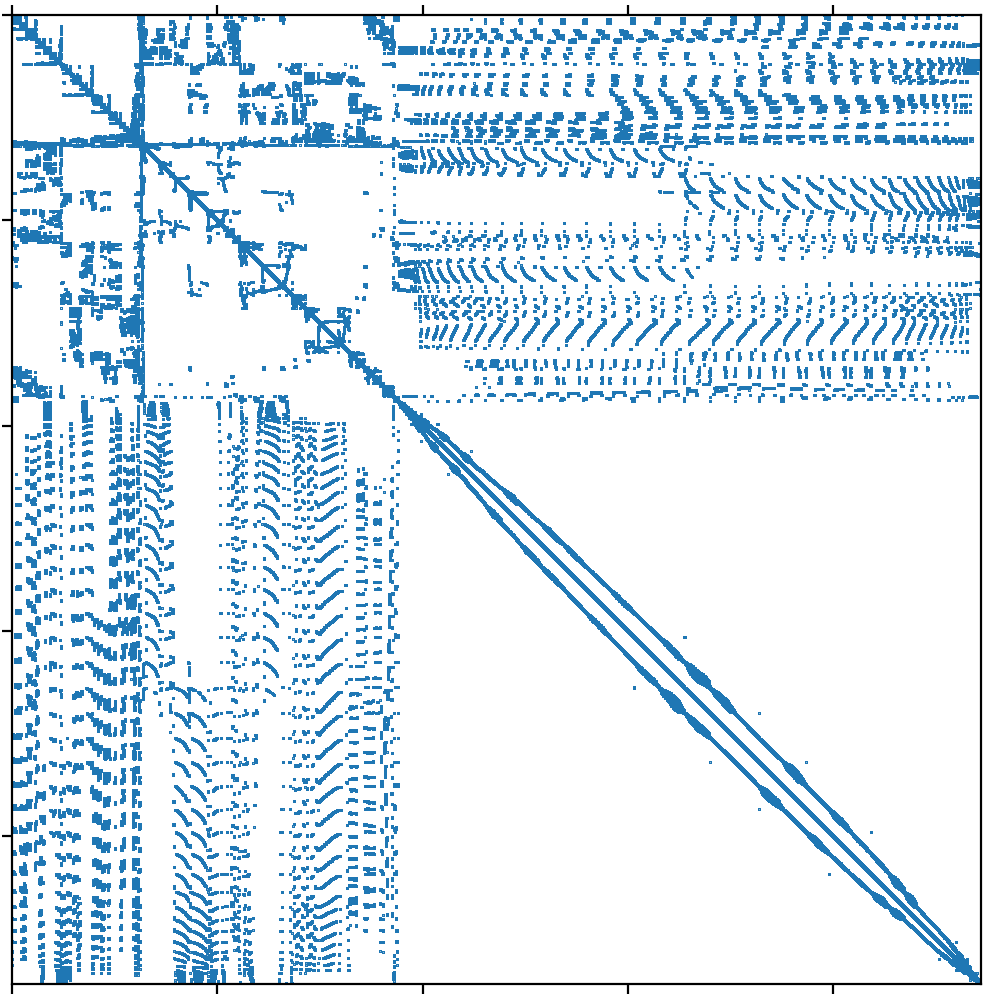
Supercomputer architectures are trending toward higher computational throughput due to the inclusion of heterogeneous compute nodes. These multi-GPU nodes increase on-node computational efficiency, while also increasing the amount of data to be communicated and the number of potential data flow paths. In this work, we characterize the performance of irregular point-to-point communication with MPI on heterogeneous compute environments through performance modeling, demonstrating the limitations of standard communication strategies for both device-aware and staging-through-host communication techniques. Presented models suggest staging communicated data through host processes then using node-aware communication strategies for high inter-node message counts. Notably, the models also predict that node-aware communication utilizing all available CPU cores to communicate inter-node data leads to the most performant strategy when communicating with a high number of nodes. Model validation is provided via a case study of irregular point-to-point communication patterns in distributed sparse matrix-vector products. Importantly, we include a discussion on the implications model predictions have on communication strategy design for emerging supercomputer architectures.
翻译:超级计算机结构正在趋向于更高的计算输送量,因为包括了多种计算节点。这些多-GPU节点提高了在节点计算效率,同时也增加了要传送的数据量和潜在数据流路径的数量。在这项工作中,我们通过性能模型描述与MPI在多种计算环境中的不规则点对点通信的性能,通过性能模型显示设备认知和中位-中位-主机通信技术的标准通信战略的局限性。推出的模型表明,通过主机程序进行传送数据,然后使用对高节点信息计数的节点通信战略。值得注意的是,这些模型还预测,利用所有可用的CPU核心进行节点数据交流的节点通信,在与大量节点进行通信时,最能的策略就是实现。模型验证是通过对分散的稀有矩阵-矢量产品中的不规则点对点通信模式通信模式的预测进行个案研究。我们也包括了模型预测对新兴超级计算机结构的通信战略设计的影响的讨论。