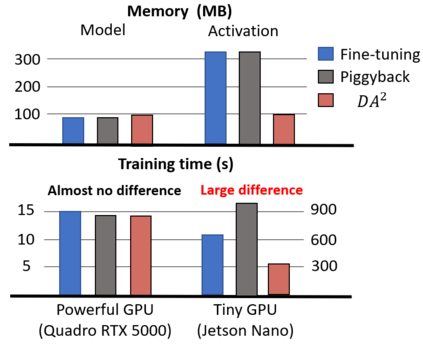
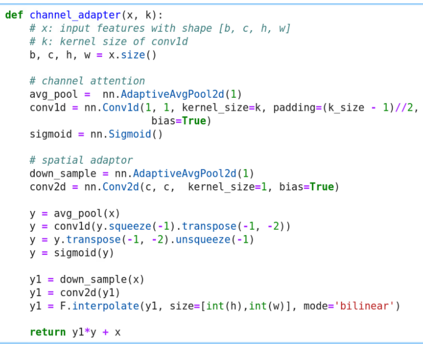
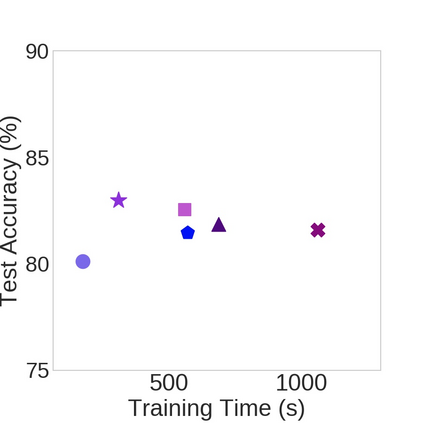
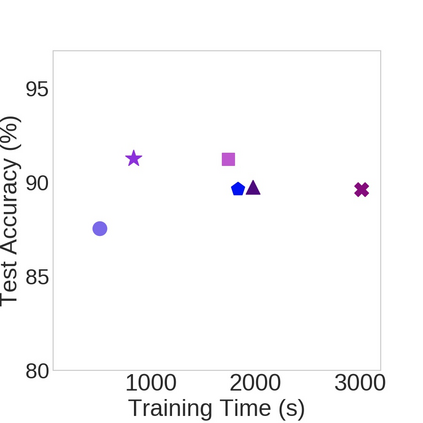
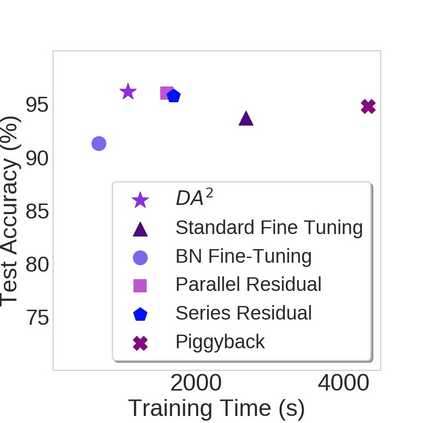
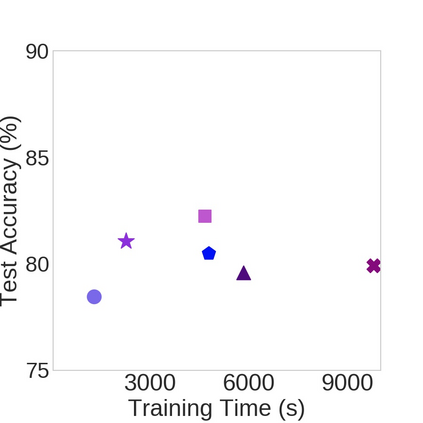
Nowadays, one practical limitation of deep neural network (DNN) is its high degree of specialization to a single task or domain (e.g. one visual domain). It motivates researchers to develop algorithms that can adapt DNN model to multiple domains sequentially, meanwhile still performing well on the past domains, which is known as multi-domain learning. Conventional methods only focus on improving accuracy with minimal parameter update, while ignoring high computing and memory usage during training, which makes it impossible to deploy into more and more widely used resource-limited edge devices, like mobile phone, IoT, embedded systems, etc. During our study, we observe that memory used for activation storage is the bottleneck that largely limits the training time and cost on edge devices. To reduce training memory usage, while keeping the domain adaption accuracy performance, in this work, we propose Deep Attention Adaptor, a novel on-device multi-domain learning method, aiming to achieve domain adaption on resource-limited edge devices in both fast and memory-efficient manner. During on-device training, DA2 freezes the weights of pre-trained backbone model to reduce the training memory consumption (i.e., no need to store activation features during backward propagation). Furthermore, to improve the adaption accuracy performance, we propose to improve the model capacity by learning a light-weight memory-efficient residual attention adaptor module. We validate DA2 on multiple datasets against state-of-the-art methods, which shows good improvement in both accuracy and training cost. Finally, we demonstrate the algorithm's efficiency on NIVDIA Jetson Nano tiny GPU, proving the proposed DA2 reduces the on-device memory consumption by 19-37x during training in comparison to the baseline methods.
翻译:目前,深神经网络(DNN)的一个实际局限性在于它高度专业化于单一任务或领域(例如一个视觉域),它激励研究人员开发能够将DNN模型按顺序调整到多个域的算法,同时仍然在以往域运行良好,这被称为多域学习。常规方法只注重提高精确度,同时忽略最低参数更新,而忽视培训期间的高计算和记忆使用率,这使得无法将更多、更广泛使用的资源有限的边缘设备,如移动电话、IOT、嵌入系统等。在我们的研究中,我们发现激活存储所用的记忆是瓶颈,它基本上限制边设备的培训时间和成本。为了减少培训记忆使用率,同时保持域的精确性能,在本工作中,我们建议深度关注调适量多域学习方法,目的是以快速和记忆效率的方式实现对资源有限的边端设备的域调整。在在线培训期间,DA2 冻结了前精度的精度模型的重量,以降低培训的精度和成本比值,以降低培训的精度,在升级期间,让我们的精度 升级升级到升级数据。