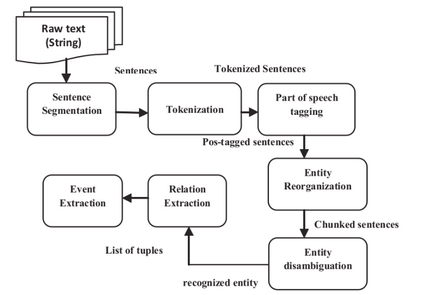
With rise of digital age, there is an explosion of information in the form of news, articles, social media, and so on. Much of this data lies in unstructured form and manually managing and effectively making use of it is tedious, boring and labor intensive. This explosion of information and need for more sophisticated and efficient information handling tools gives rise to Information Extraction(IE) and Information Retrieval(IR) technology. Information Extraction systems takes natural language text as input and produces structured information specified by certain criteria, that is relevant to a particular application. Various sub-tasks of IE such as Named Entity Recognition, Coreference Resolution, Named Entity Linking, Relation Extraction, Knowledge Base reasoning forms the building blocks of various high end Natural Language Processing (NLP) tasks such as Machine Translation, Question-Answering System, Natural Language Understanding, Text Summarization and Digital Assistants like Siri, Cortana and Google Now. This paper introduces Information Extraction technology, its various sub-tasks, highlights state-of-the-art research in various IE subtasks, current challenges and future research directions.
翻译:随着数字时代的崛起,信息以新闻、文章、社交媒体等形式涌现。许多这类数据都以非结构化的形式和人工管理及有效利用这种形式出现,而且人工管理和有效利用这种形式是乏味的、无聊的和劳动密集型的。这种信息爆炸和对更先进、效率更高的信息处理工具的需求产生了信息提取和检索技术。信息提取系统采用自然语言文本作为输入,并生成与特定应用有关的特定标准规定的结构化信息。信息提取技术的各种子任务,如命名实体识别、引用分辨率、命名实体链接、Relation采掘、知识库推理构成各种高端自然语言处理(NLP)任务的构件,如机器翻译、问题解答系统、自然语言理解、文本解析和数字助理,如Siri、Cortana和Google Now。本文介绍了信息提取技术、其各种子任务、突出介绍各种小任务、当前挑战和未来研究方向。