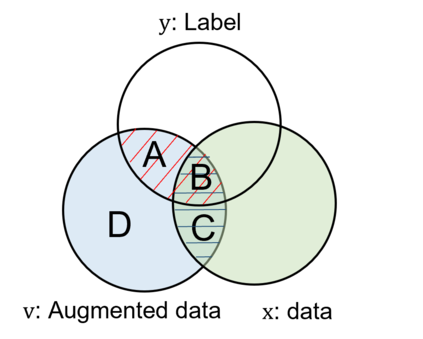
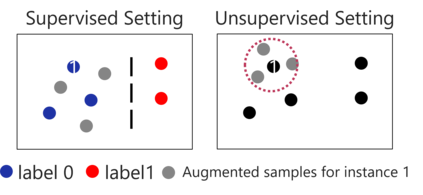
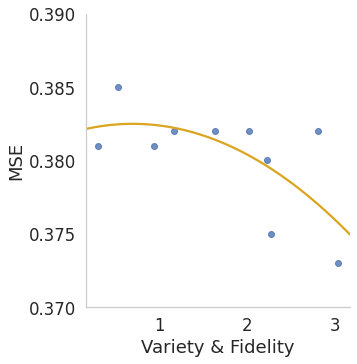
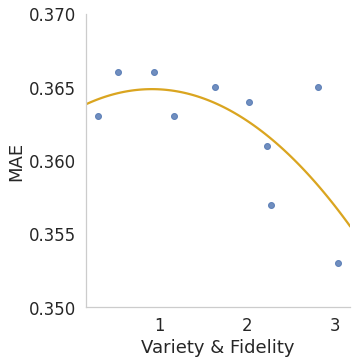
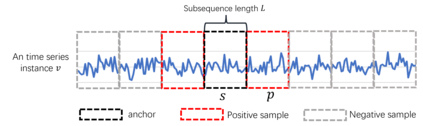
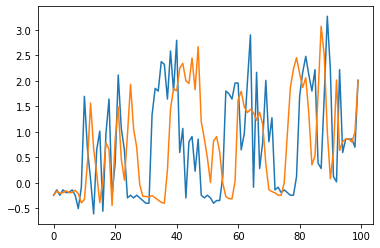
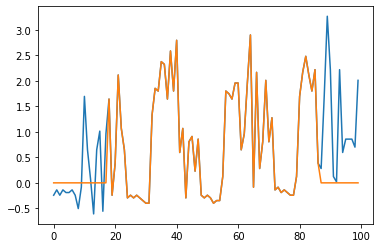
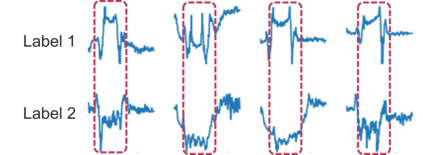
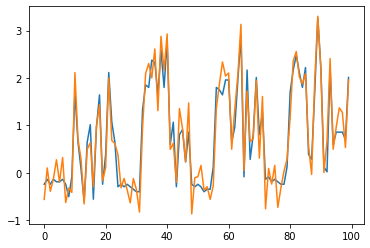
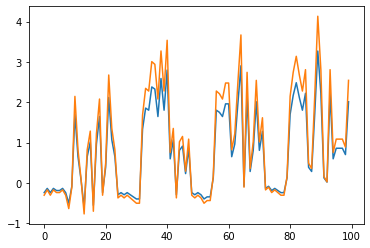
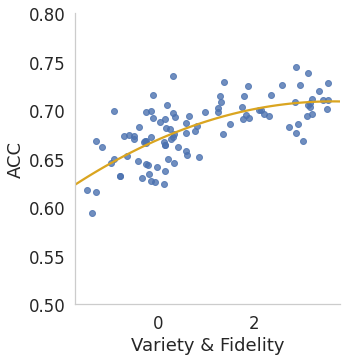
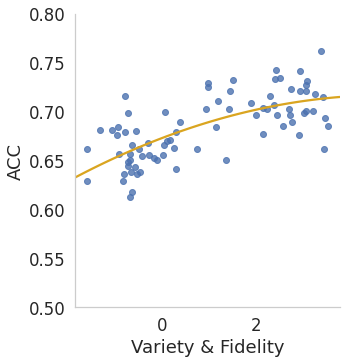
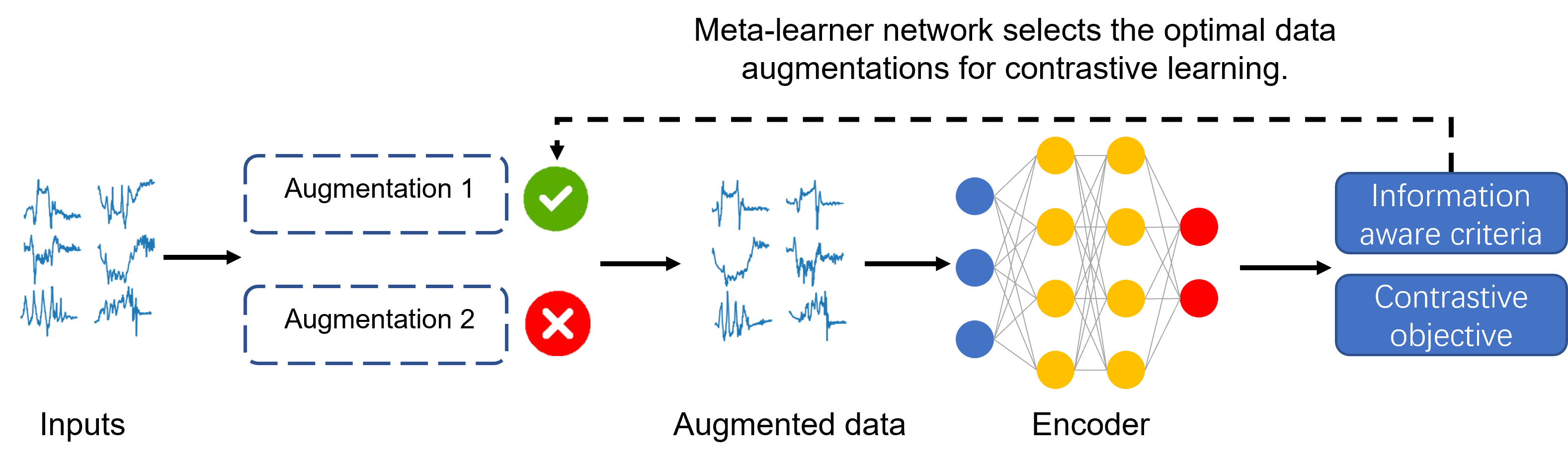
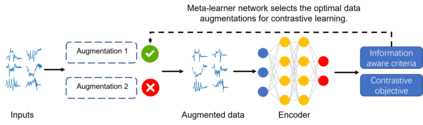Various contrastive learning approaches have been proposed in recent years and achieve significant empirical success. While effective and prevalent, contrastive learning has been less explored for time series data. A key component of contrastive learning is to select appropriate augmentations imposing some priors to construct feasible positive samples, such that an encoder can be trained to learn robust and discriminative representations. Unlike image and language domains where ``desired'' augmented samples can be generated with the rule of thumb guided by prefabricated human priors, the ad-hoc manual selection of time series augmentations is hindered by their diverse and human-unrecognizable temporal structures. How to find the desired augmentations of time series data that are meaningful for given contrastive learning tasks and datasets remains an open question. In this work, we address the problem by encouraging both high \textit{fidelity} and \textit{variety} based upon information theory. A theoretical analysis leads to the criteria for selecting feasible data augmentations. On top of that, we propose a new contrastive learning approach with information-aware augmentations, InfoTS, that adaptively selects optimal augmentations for time series representation learning. Experiments on various datasets show highly competitive performance with up to 12.0\% reduction in MSE on forecasting tasks and up to 3.7\% relative improvement in accuracy on classification tasks over the leading baselines.
翻译:近年来,已提出多种对比学习方法并取得了显著的实验效果。虽然这些方法很有效且流行,但是对于时间序列数据,对比学习的探索却较少。对比学习的一个关键组成部分是选择适当的扩充方式,通过施加一些先验条件来构建合理的正样本,使得编码器可以学习到健壮且有区分性的表示。与可以通过拟定先验条件指导的规则生成所需的扩充样本的图像和语言领域不同,手动选择时间序列扩充方式的一些定义是这种扩充方式的不同,因而这些定义不易于理解。对于给定的对比学习任务和数据集,如何找到适合时间序列数据的所需扩充方式仍然是一个未解决的问题。在这项工作中,我们通过信息理论来鼓励高保真度和多样化。理论分析导致选择可行数据扩充的标准。在此基础上,我们提出了一种新的信息感知扩充的对比学习方法 InfoTS,该方法自适应选择时间序列表示学习的最佳扩充方法。在各种数据集的实验中,我们的方法显示出高竞争性能,预测任务的均方误差可以减少高达 12.0%,分类任务的准确度相对提高高达 3.7%,较领先的基准线有明显提升。