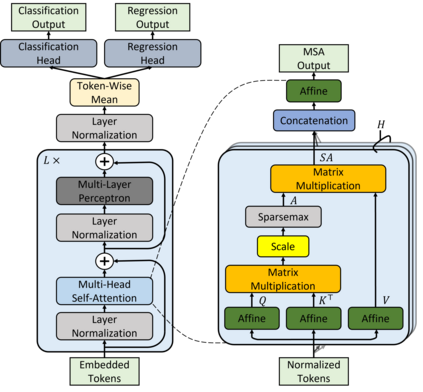
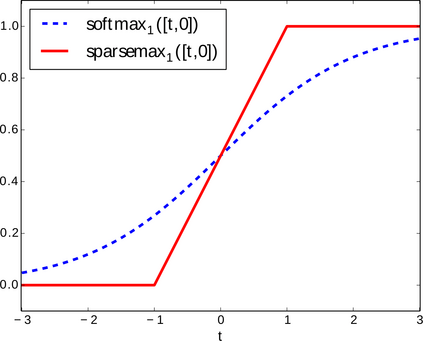
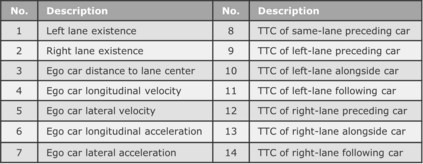
Attention networks such as transformers have been shown powerful in many applications ranging from natural language processing to object recognition. This paper further considers their robustness properties from both theoretical and empirical perspectives. Theoretically, we formulate a variant of attention networks containing linearized layer normalization and sparsemax activation, and reduce its robustness verification to a Mixed Integer Programming problem. Apart from a na\"ive encoding, we derive tight intervals from admissible perturbation regions and examine several heuristics to speed up the verification process. More specifically, we find a novel bounding technique for sparsemax activation, which is also applicable to softmax activation in general neural networks. Empirically, we evaluate our proposed techniques with a case study on lane departure warning and demonstrate a performance gain of approximately an order of magnitude. Furthermore, although attention networks typically deliver higher accuracy than general neural networks, contrasting its robustness against a similar-sized multi-layer perceptron surprisingly shows that they are not necessarily more robust.
翻译:在从自然语言处理到物体识别等许多应用中,变压器等关注网络都表现出强大的力量。本文件进一步从理论和实验角度考虑其稳健性能。理论上,我们设计了一个包含线性层正常化和稀释轴激活的注意网络的变体,并将其稳健性核查降低为混合整数编程问题。除了“鼻线”编码外,我们从可受理的扰动区域获得较紧的间隔,并研究一些加速核查过程的惯性。更具体地说,我们发现了一种稀释式激活的新型捆绑技术,它也适用于一般神经网络中的软式最大激活。我们随机地评估了我们提出的技术,进行了关于航道偏离警告的案例研究,并展示了大致数量级的性能增益。此外,尽管注意网络通常比一般神经网络的精度更高,但与类似大小的多层感官网络的强度相比,令人惊讶地表明它们不一定更强。