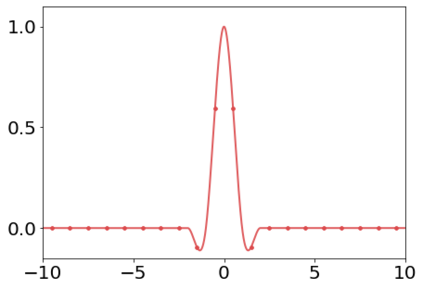
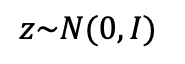Metrics for evaluating generative models aim to measure the discrepancy between real and generated images. The often-used Frechet Inception Distance (FID) metric, for example, extracts "high-level" features using a deep network from the two sets. However, we find that the differences in "low-level" preprocessing, specifically image resizing and compression, can induce large variations and have unforeseen consequences. For instance, when resizing an image, e.g., with a bilinear or bicubic kernel, signal processing principles mandate adjusting prefilter width depending on the downsampling factor, to antialias to the appropriate bandwidth. However, commonly-used implementations use a fixed-width prefilter, resulting in aliasing artifacts. Such aliasing leads to corruptions in the feature extraction downstream. Next, lossy compression, such as JPEG, is commonly used to reduce the file size of an image. Although designed to minimally degrade the perceptual quality of an image, the operation also produces variations downstream. Furthermore, we show that if compression is used on real training images, FID can actually improve if the generated images are also subsequently compressed. This paper shows that choices in low-level image processing have been an underappreciated aspect of generative modeling. We identify and characterize variations in generative modeling development pipelines, provide recommendations based on signal processing principles, and release a reference implementation to facilitate future comparisons.
翻译:用于评价基因模型的计量方法旨在测量真实图像和生成图像之间的差异。例如,通常使用的Frechet Invition Convention Learter(FID)衡量标准,利用两组的深网络提取“高层次”特征。然而,我们发现,“低层次”预处理的差别,特别是图像重新调整和压缩,可能导致很大的变异和不可预见的后果。例如,在对图像进行重新调整时,例如,用双线或双立方内核,信号处理原则授权根据下层取样系数调整预过滤器宽度,到对应的带宽。然而,通常使用的执行方法使用固定宽度的预过滤器,使用固定宽度的预过滤器,导致人工制品。然而,我们发现,“低层”预处理方法的差别可能导致特征提取下游的腐败。接下来,诸如JPEGEG等损失压缩通常用来减少图像的档案大小。虽然设计模型旨在尽可能降低图像的感知性质量,但操作也会产生下游变化。此外,我们还表明,如果实际培训图像中使用压缩的模型,那么,那么,IMFID就能够改进。