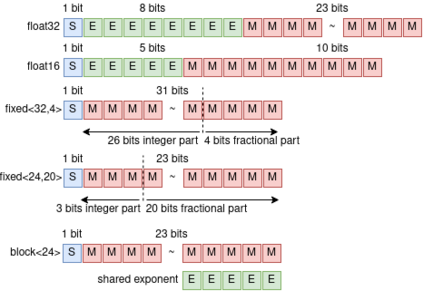
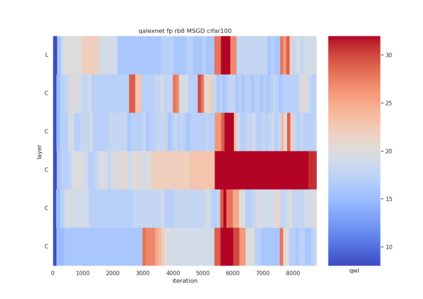
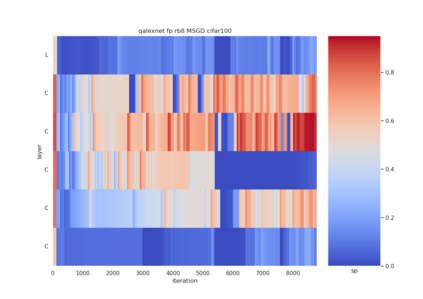
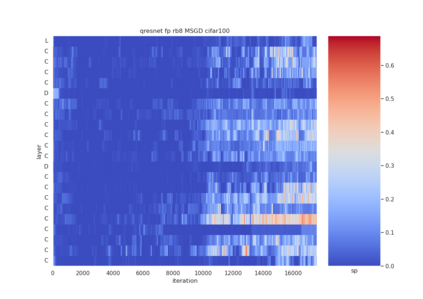
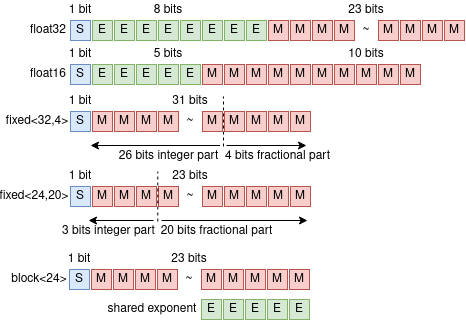
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Little work on quantized training exists and usually, existing approaches re-quire full precision refinement afterwards or enforce a global word length across the whole DNN. This leads to suboptimal bitwidth-to-layers assignments and re-source usage. Recognizing these limits, we introduce ADEPT, a new quantized sparsifying training strategy using information theory-based intra-epoch precision switching to find on a per-layer basis the lowest precision that causes no quantization-induced information loss while keeping precision high enough for future learning steps to not suffer from vanishing gradients, producing a fully quantized DNN. Based on a bitwidth-weighted MAdds performance model, our approach achieves an average speedup of 1.26 and model size reduction of 0.53 compared to standard training in float32 with an average accuracy increase of 0.98% on AlexNet/ResNet on CIFAR10/100.
翻译:量化是一种减少深神经网络(DNNs)培训和推断时间的技术,对于资源受限环境或时间关键推断应用中的培训至关重要。最先进的(SOTA)方法侧重于培训后量化,即为加快推断,对预先培训的DNNs进行量化,在量化培训方面几乎没有什么工作,而且通常,现有方法在之后重新要求完全精细的完善,或在整个DNNN执行全球单词长度。这导致在资源受限环境或时间紧要的推断应用中进行不最优化的位至层任务分配和再源使用。我们认识到这些限制,采用了ADEPT,这是一个新的量化的强化培训战略,使用基于信息理论的内部精度精确度转换,以找到不造成量化导致信息损失的最低精确度,同时保持足够精确度,以便今后学习步骤不因梯度消失而受损失,从而产生完全量化的DNNN。根据微弱缩缩缩缩缩的MAdds性能再使用。我们采用的方法,采用基于基于信息理论的新的四分级测试,即精度测试战略,在一级基础上,在1.26年至10年平均水平的AS勒标准标准中,在1比0.18的AS标准中,在1比0.1比0.1比0.10的ASAR标准标准中,在1比0.1,在1比0.1比0.1比0.1比0.10的ASAAR标准中,在0.1,在0.1。