
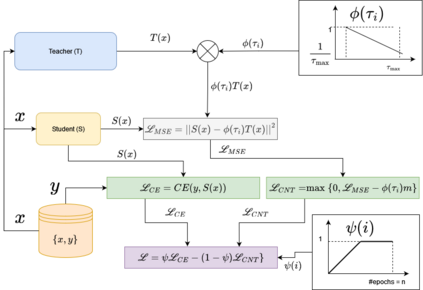
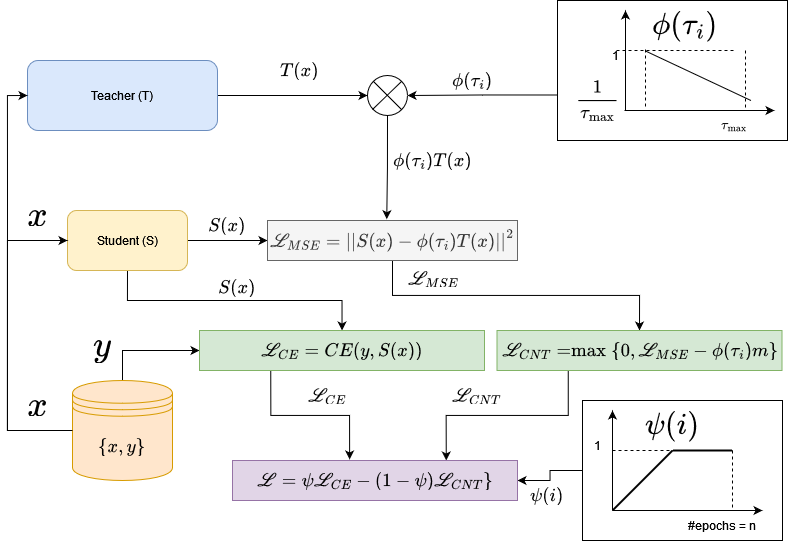
Knowledge Distillation (KD) has been extensively used for natural language understanding (NLU) tasks to improve a small model's (a student) generalization by transferring the knowledge from a larger model (a teacher). Although KD methods achieve state-of-the-art performance in numerous settings, they suffer from several problems limiting their performance. It is shown in the literature that the capacity gap between the teacher and the student networks can make KD ineffective. Additionally, existing KD techniques do not mitigate the noise in the teacher's output: modeling the noisy behaviour of the teacher can distract the student from learning more useful features. We propose a new KD method that addresses these problems and facilitates the training compared to previous techniques. Inspired by continuation optimization, we design a training procedure that optimizes the highly non-convex KD objective by starting with the smoothed version of this objective and making it more complex as the training proceeds. Our method (Continuation-KD) achieves state-of-the-art performance across various compact architectures on NLU (GLUE benchmark) and computer vision tasks (CIFAR-10 and CIFAR-100).
翻译:知识蒸馏(KD)被广泛用于自然语言理解(NLU)任务,目的是通过从更大的模型(教师)传授知识来改进小型模型(学生)的普及化。虽然KD方法在许多环境中取得了最先进的表现,但它们遇到了若干限制其业绩的问题。文献显示,教师和学生网络的能力差距可以使KD失去效力。此外,现有的KD技术不能减轻教师产出中的噪音:模拟教师的吵闹行为可以分散学生学习更有用的特征的注意力。我们提出了一种新的KD方法,以解决这些问题并促进与以往技术相比的培训。在继续优化的激励下,我们设计了一个培训程序,从这一目标的平滑版本开始,随着培训的进行而使其更为复杂。我们的方法(继续-KD)在NLU(GLUE基准)和计算机视觉任务(CIFAR-10和CIFAR-100)的各种紧凑结构中达到了最先进的业绩。
相关内容

Source: Apple - iOS 8

