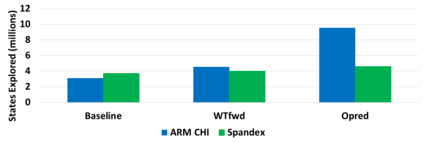
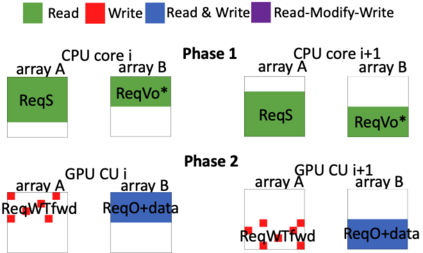
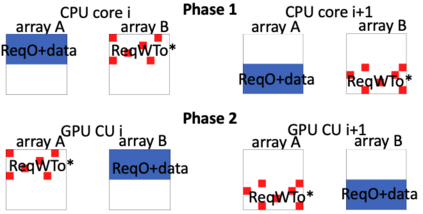
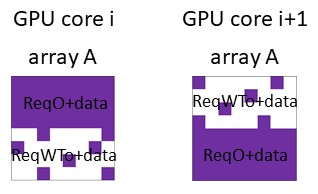
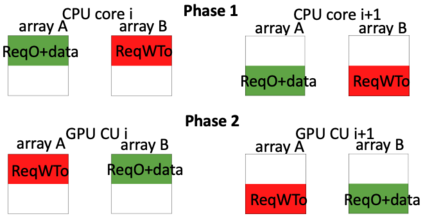
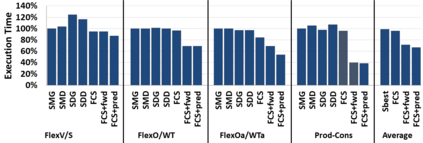
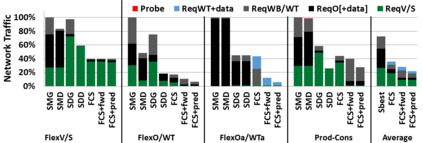
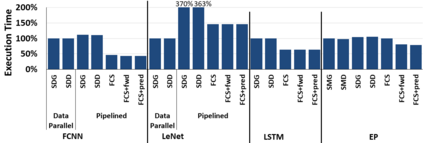
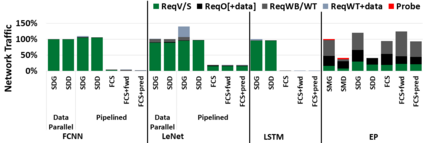
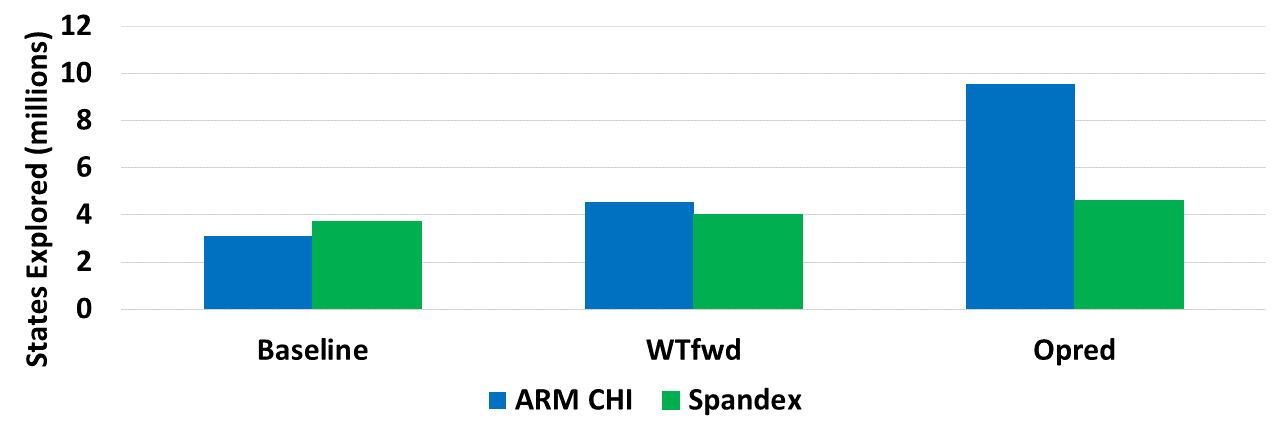
Hardware specialization is becoming a key enabler of energyefficient performance. Future systems will be increasingly heterogeneous, integrating multiple specialized and programmable accelerators, each with different memory demands. Traditionally, communication between accelerators has been inefficient, typically orchestrated through explicit DMA transfers between different address spaces. More recently, industry has proposed unified coherent memory which enables implicit data movement and more data reuse, but often these interfaces limit the coherence flexibility available to heterogeneous systems. This paper demonstrates the benefits of fine-grained coherence specialization for heterogeneous systems. We propose an architecture that enables low-complexity independent specialization of each individual coherence request in heterogeneous workloads by building upon a simple and flexible baseline coherence interface, Spandex. We then describe how to optimize individual memory requests to improve cache reuse and performance-critical memory latency in emerging heterogeneous workloads. Collectively, our techniques enable significant gains, reducing execution time by up to 61% or network traffic by up to 99% while adding minimal complexity to the Spandex protocol.
翻译:硬件专业化正在成为节能性能的关键促进因素。 未来系统将日益多样化, 整合多种专门和可编程的加速器, 每一个系统都有不同的记忆需求。 传统上, 加速器之间的沟通效率一直低下, 通常是在不同地址空间之间通过明确的 DMA 传输进行。 最近, 工业界提出了统一一致的记忆, 从而允许隐含的数据移动和更多的数据再利用, 但是这些界面往往限制了多元系统的一致性灵活性。 本文展示了精细区分的系统一致性专业化的好处。 我们提出了一个结构, 借助一个简单灵活的基线一致性界面Spandex, 使不同工作量中每个个人的一致性要求都能独立实现低复杂性的专业化。 我们然后描述了如何优化个人记忆请求, 以改善缓存再利用和新出现不同工作量中的性能- 关键记忆耐久性。 我们的技术可以共同带来重大收益, 将执行时间降低到61%, 网络流量降低到99%, 同时给Spandex 协议增加最小的复杂度 。