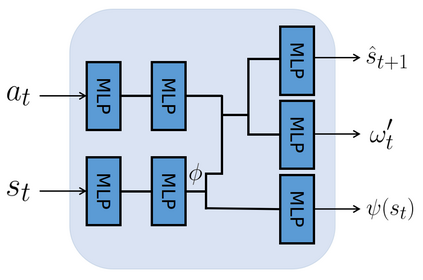
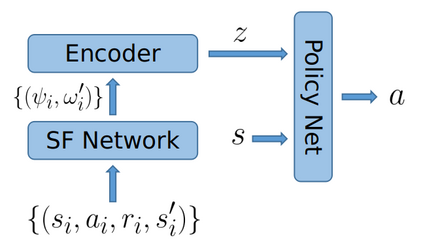
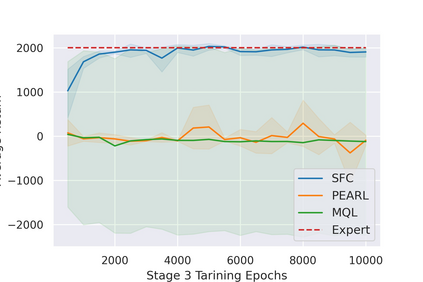
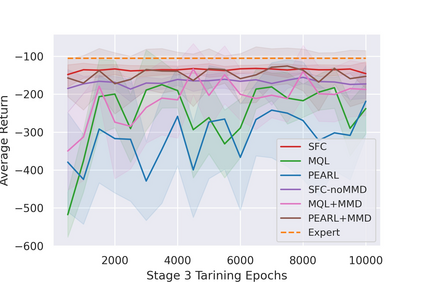
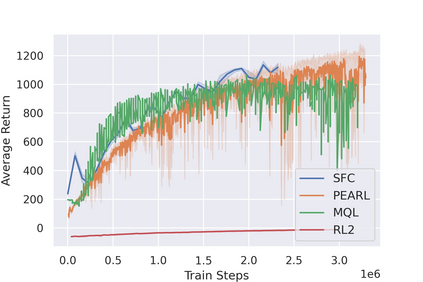
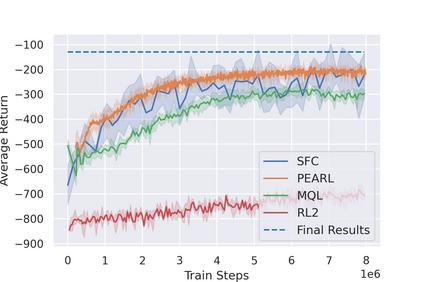
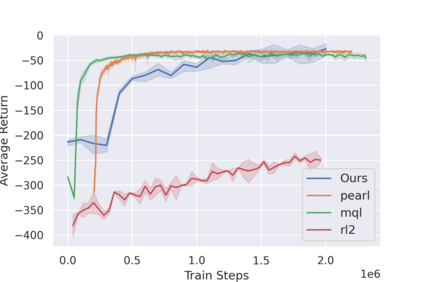
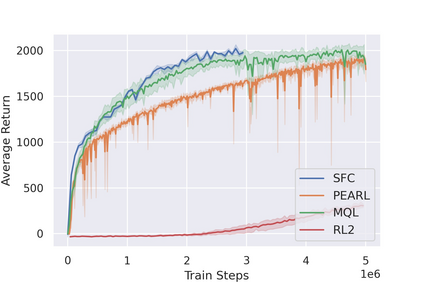
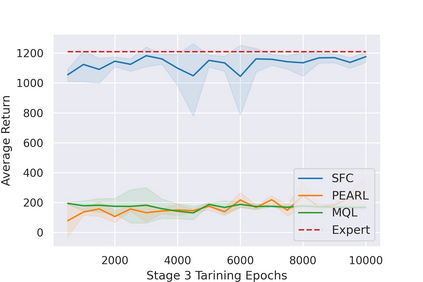
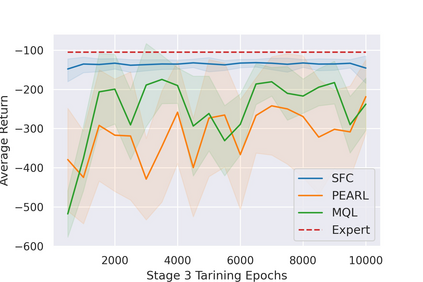
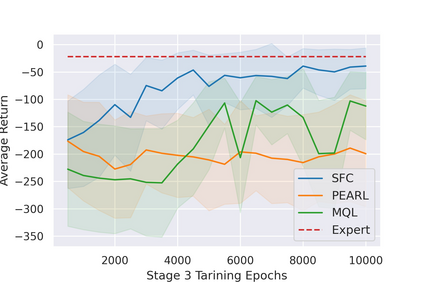
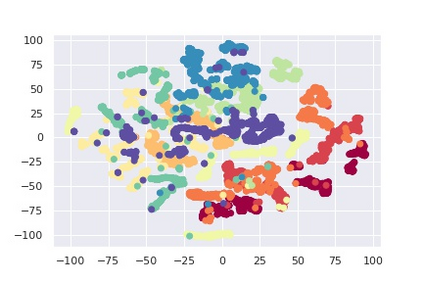
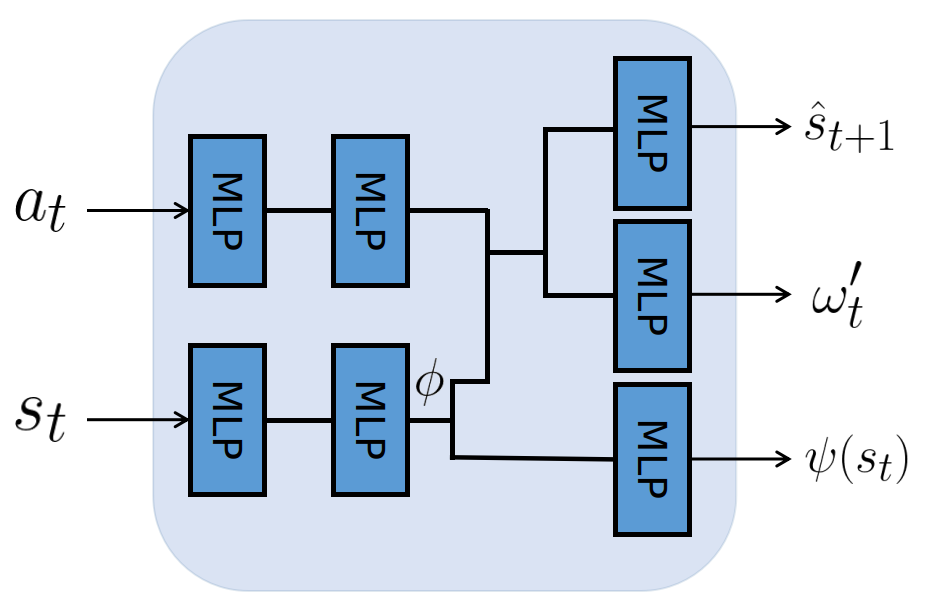
Most reinforcement learning (RL) methods only focus on learning a single task from scratch and are not able to use prior knowledge to learn other tasks more effectively. Context-based meta RL techniques are recently proposed as a possible solution to tackle this. However, they are usually less efficient than conventional RL and may require many trial-and-errors during training. To address this, we propose a novel meta-RL approach that achieves competitive performance comparing to existing meta-RL algorithms, while requires significantly fewer environmental interactions. By combining context variables with the idea of decomposing reward in successor feature framework, our method does not only learn high-quality policies for multiple tasks simultaneously but also can quickly adapt to new tasks with a small amount of training. Compared with state-of-the-art meta-RL baselines, we empirically show the effectiveness and data efficiency of our method on several continuous control tasks.
翻译:多数强化学习(RL)方法仅侧重于从零开始学习单一任务,无法利用先前的知识来更有效地学习其他任务;最近提出了基于背景的元RL技术,作为解决这一问题的可能解决办法;然而,这些技术通常比常规RL效率低,在培训期间可能需要许多试探和试探。为了解决这个问题,我们建议采用一种新的元-RL方法,与现有的元-RL算法相比,实现竞争性业绩,同时需要大大减少环境互动。通过将上下文变量与在后续特征框架中分解奖赏的概念相结合,我们的方法不仅同时学习多项任务的高质量政策,而且还可以迅速适应少量培训的新任务。与最新水平的元-RL基线相比,我们从经验上展示了我们方法在几项连续控制任务上的有效性和数据效率。