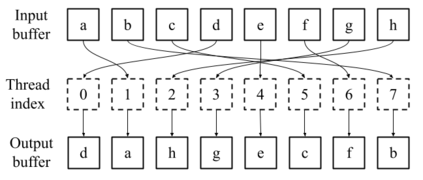
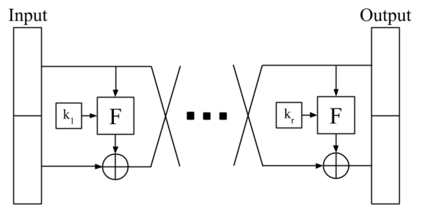
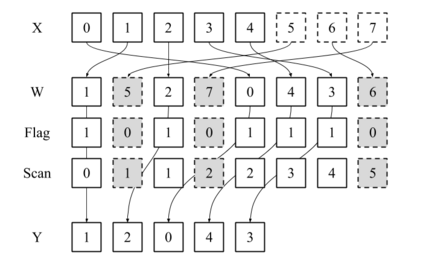
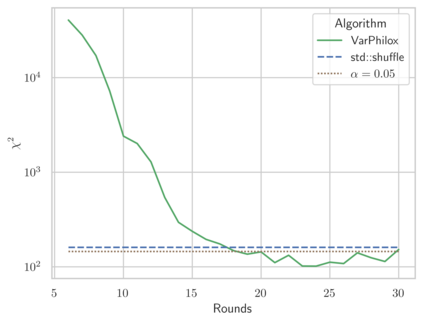
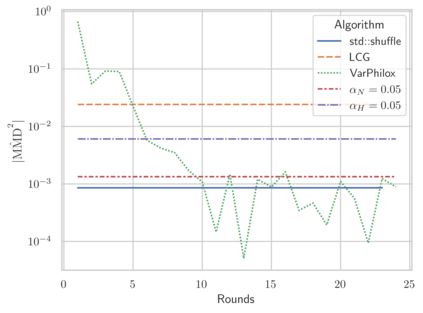
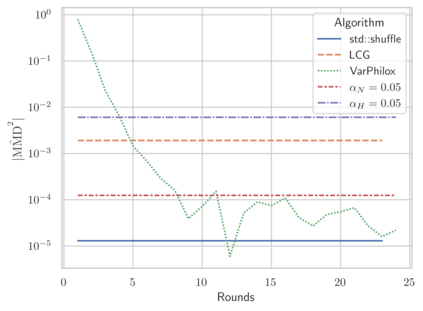
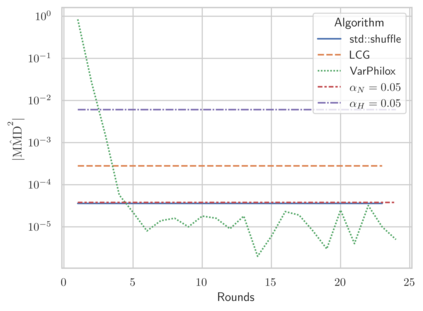
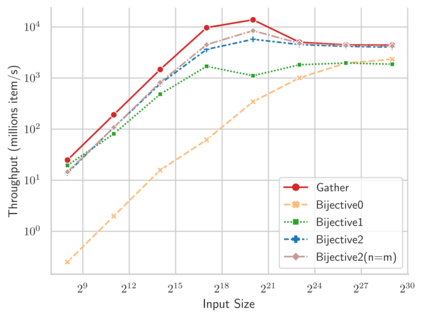
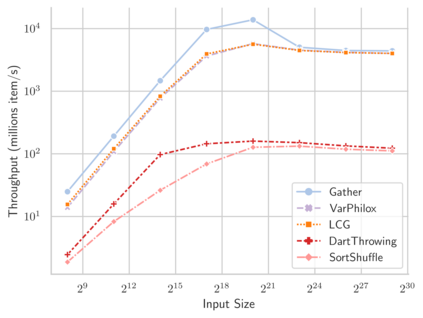
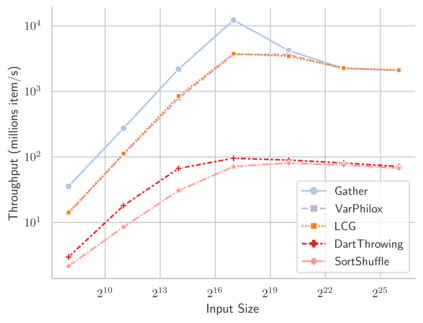
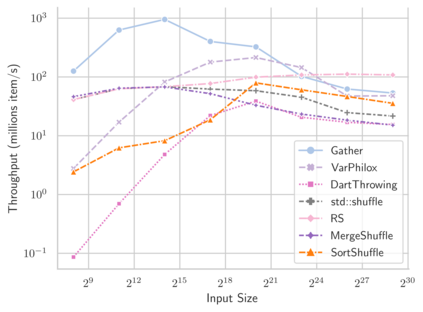
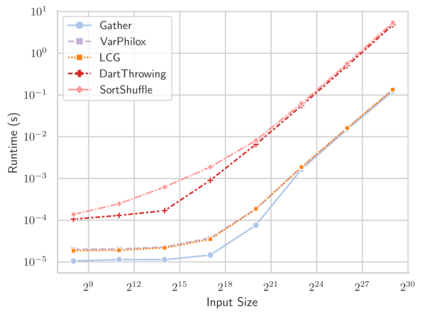
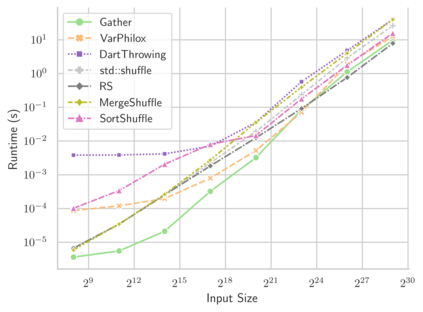
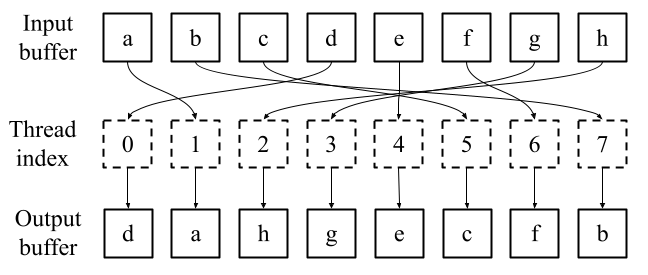
Linear-time algorithms that are traditionally used to shuffle data on CPUs, such as the method of Fisher-Yates, are not well suited to implementation on GPUs due to inherent sequential dependencies, and existing parallel shuffling algorithms are unsuitable for GPU architectures because they incur a large number of read/write operations to high latency global memory. To address this, we provide a method of generating pseudo-random permutations in parallel by fusing suitable pseudo-random bijective functions with stream compaction operations. Our algorithm, termed `bijective shuffle' trades increased per-thread arithmetic operations for reduced global memory transactions. It is work-efficient, deterministic, and only requires a single global memory read and write per shuffle input, thus maximising use of global memory bandwidth. To empirically demonstrate the correctness of the algorithm, we develop a statistical test for the quality of pseudo-random permutations based on kernel space embeddings. Experimental results show that the bijective shuffle algorithm outperforms competing algorithms on GPUs, showing improvements of between one and two orders of magnitude and approaching peak device bandwidth.
翻译:传统上用于打乱CPU数据的线性时间算法,例如Fisher-Yates方法,由于固有的相继依附性,不适合在 GPU 上执行,而现有的平行打乱算法,由于GPU 结构中产生大量读/写操作,形成高悬浮全球记忆。为了解决这个问题,我们提供了一种方法,通过在流压操作中使用适当的假假随机双向函数来同时产生假随机变异。我们的算法,称为“弹式打乱”交易,增加了用于减少全球内存交易的单读计算操作。它具有工作效率,具有确定性,只需要一个单一的全球内存读和写一次打乱输入,从而最大限度地使用全球内存带宽度。为了从经验上证明算法的正确性,我们开发了一个基于内嵌空间嵌入的假随机变异特性的统计测试。实验结果显示,双向打乱算法在GPPUPOL 设备上竞合的峰级算法,显示GPPUPOL 和最高峰级设备之间的改进程度。