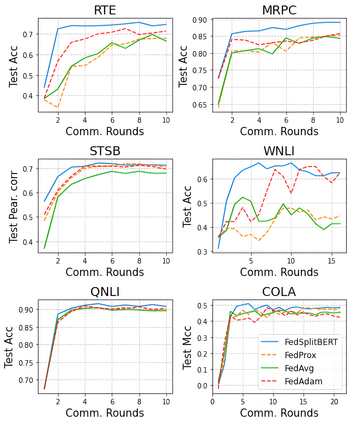
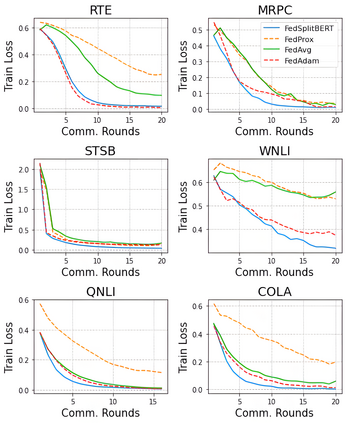
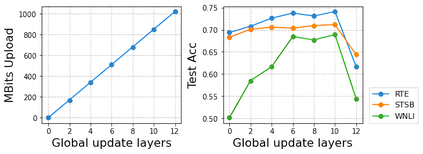
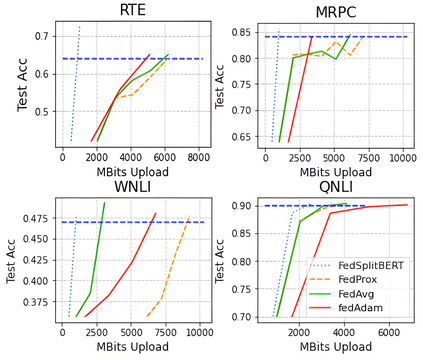
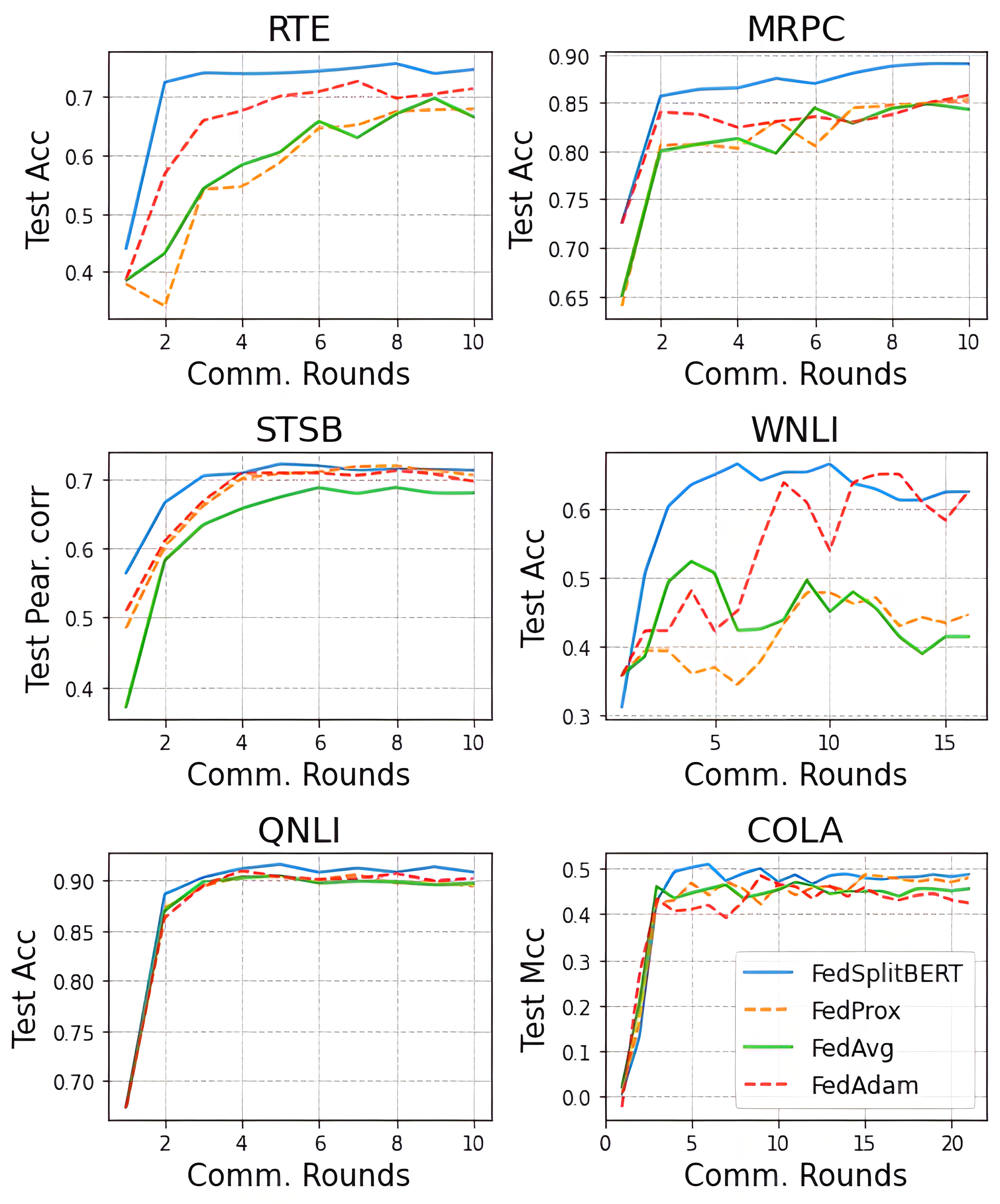
Pre-trained BERT models have achieved impressive performance in many natural language processing (NLP) tasks. However, in many real-world situations, textual data are usually decentralized over many clients and unable to be uploaded to a central server due to privacy protection and regulations. Federated learning (FL) enables multiple clients collaboratively to train a global model while keeping the local data privacy. A few researches have investigated BERT in federated learning setting, but the problem of performance loss caused by heterogeneous (e.g., non-IID) data over clients remain under-explored. To address this issue, we propose a framework, FedSplitBERT, which handles heterogeneous data and decreases the communication cost by splitting the BERT encoder layers into local part and global part. The local part parameters are trained by the local client only while the global part parameters are trained by aggregating gradients of multiple clients. Due to the sheer size of BERT, we explore a quantization method to further reduce the communication cost with minimal performance loss. Our framework is ready-to-use and compatible to many existing federated learning algorithms, including FedAvg, FedProx and FedAdam. Our experiments verify the effectiveness of the proposed framework, which outperforms baseline methods by a significant margin, while FedSplitBERT with quantization can reduce the communication cost by $11.9\times$.
翻译:受过培训的BERT模型在许多自然语言处理(NLP)任务中取得了令人印象深刻的成绩。然而,在许多现实世界中,文本数据通常分散给许多客户,由于隐私保护和监管,无法上传到中央服务器。联邦学习(FL)使多个客户能够合作培训全球模型,同时保持当地数据隐私。一些研究在联邦学习环境中对BERT进行了调查,但是由于对客户的不同数据(例如非IID)造成的业绩损失问题仍未得到充分探讨。为解决这一问题,我们提议了一个框架,即FedSplitBERT,处理不同数据,并通过将BERT编码层分为地方部分和全球部分来降低通信成本。本地部分参数仅由当地客户培训,而全球部分参数则通过综合多个客户的梯度来培训。由于BERT的庞大规模,我们探索了一种量化方法,以进一步降低通信成本,同时尽量减少绩效损失。我们的框架已经准备使用,并且与许多现有的FedScritelex学习成本比值一致,同时由FedAvBFedS格式进行一项重大的FedS格式的测试,而通过FedAxxFedFDFed和FedSquist