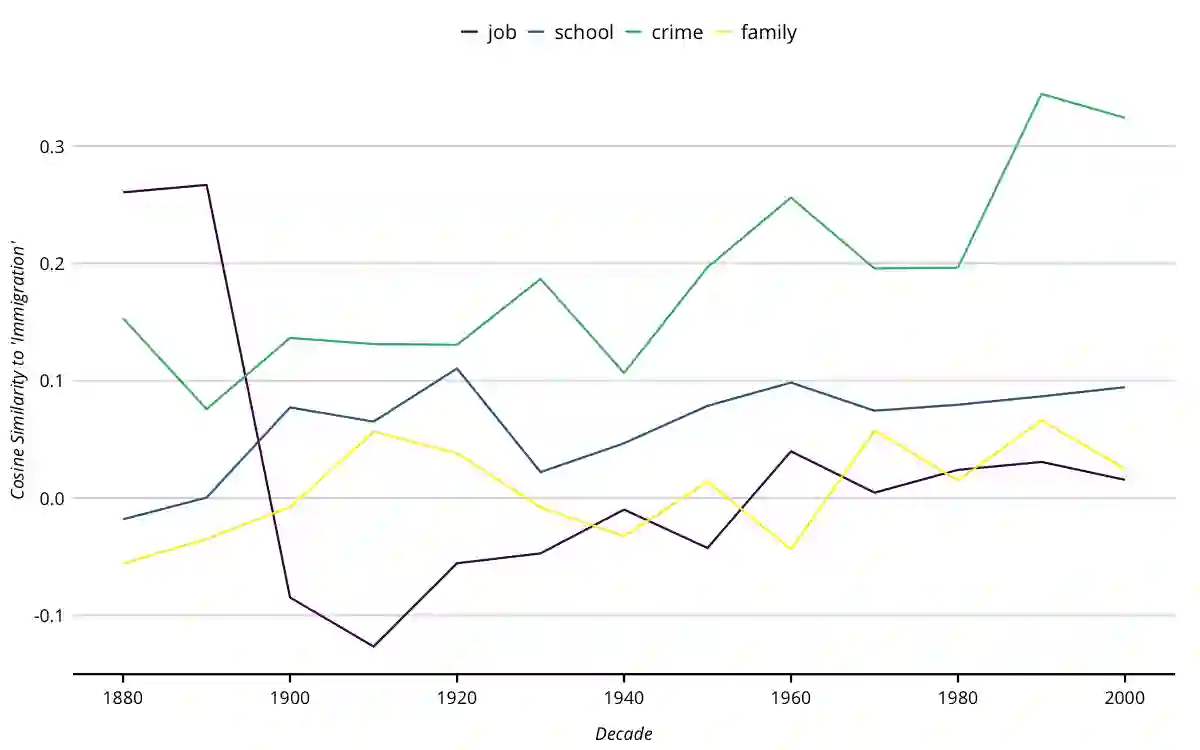
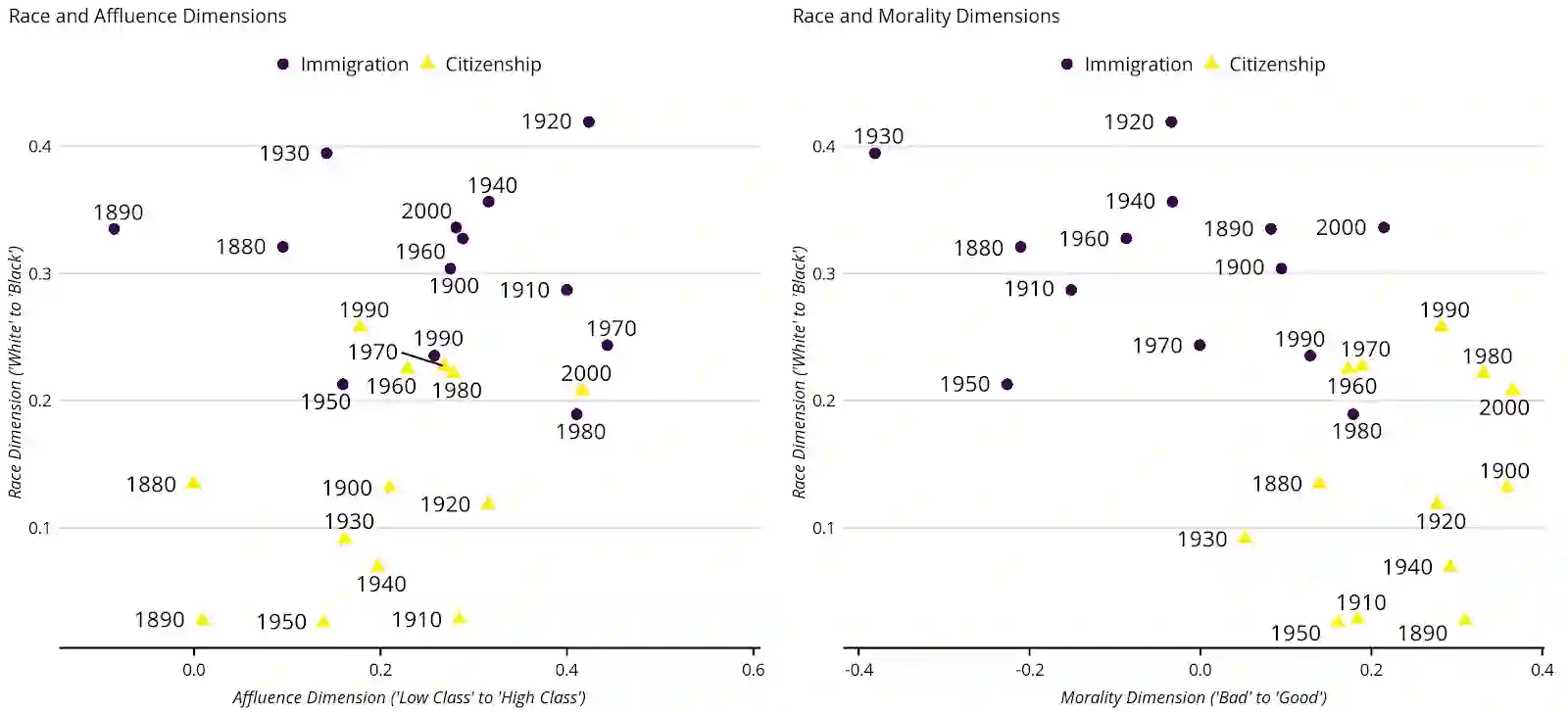
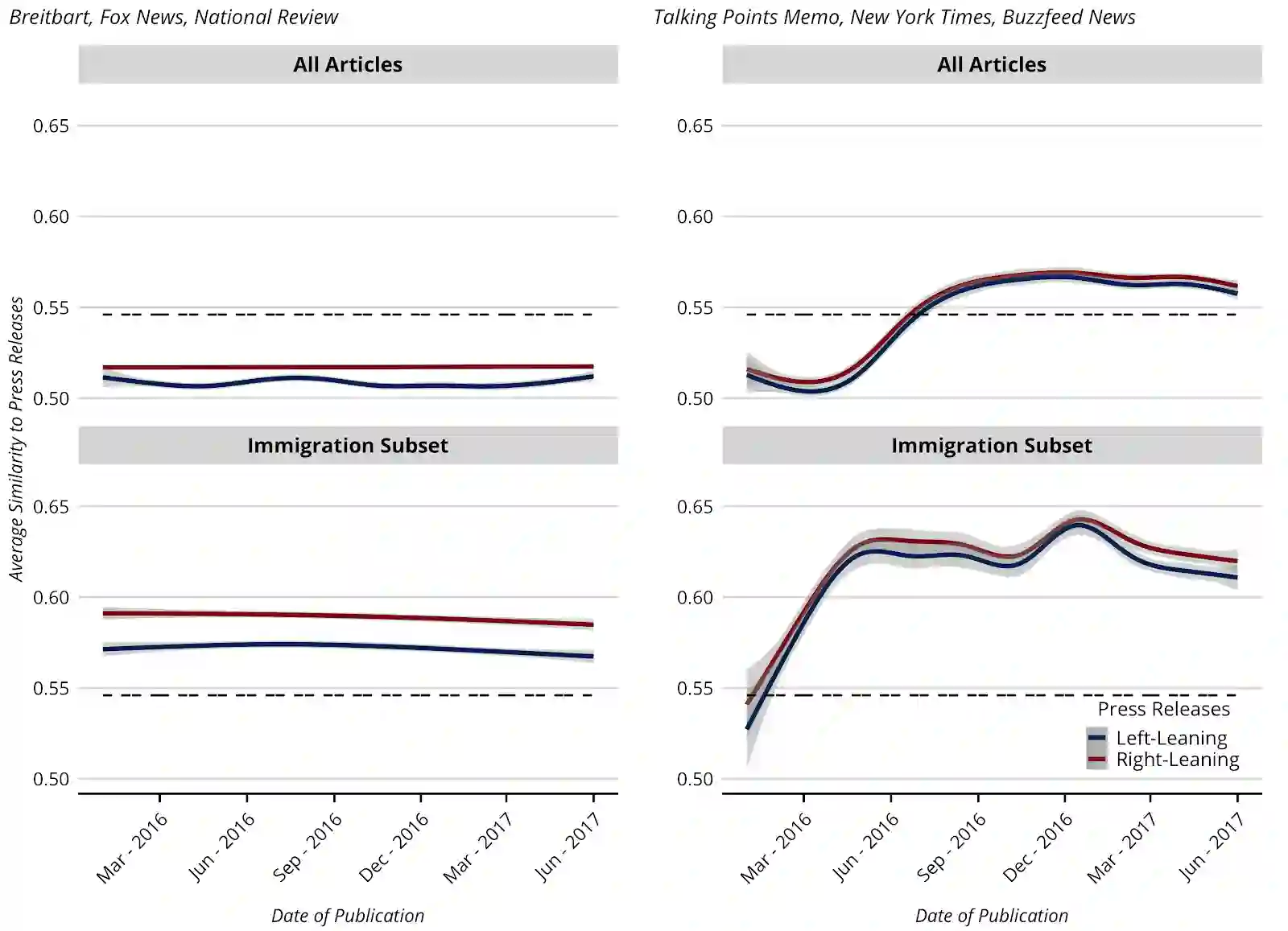
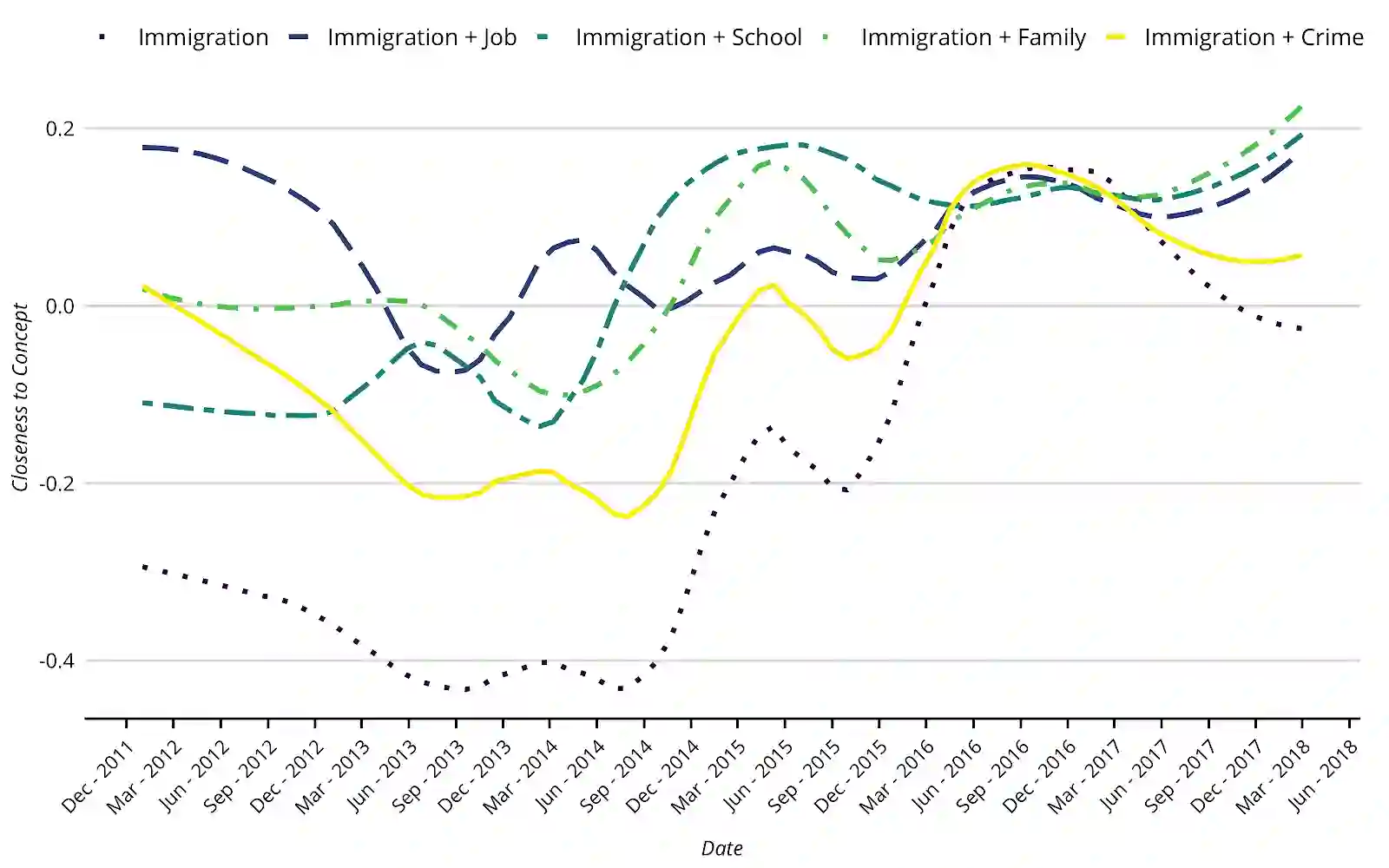
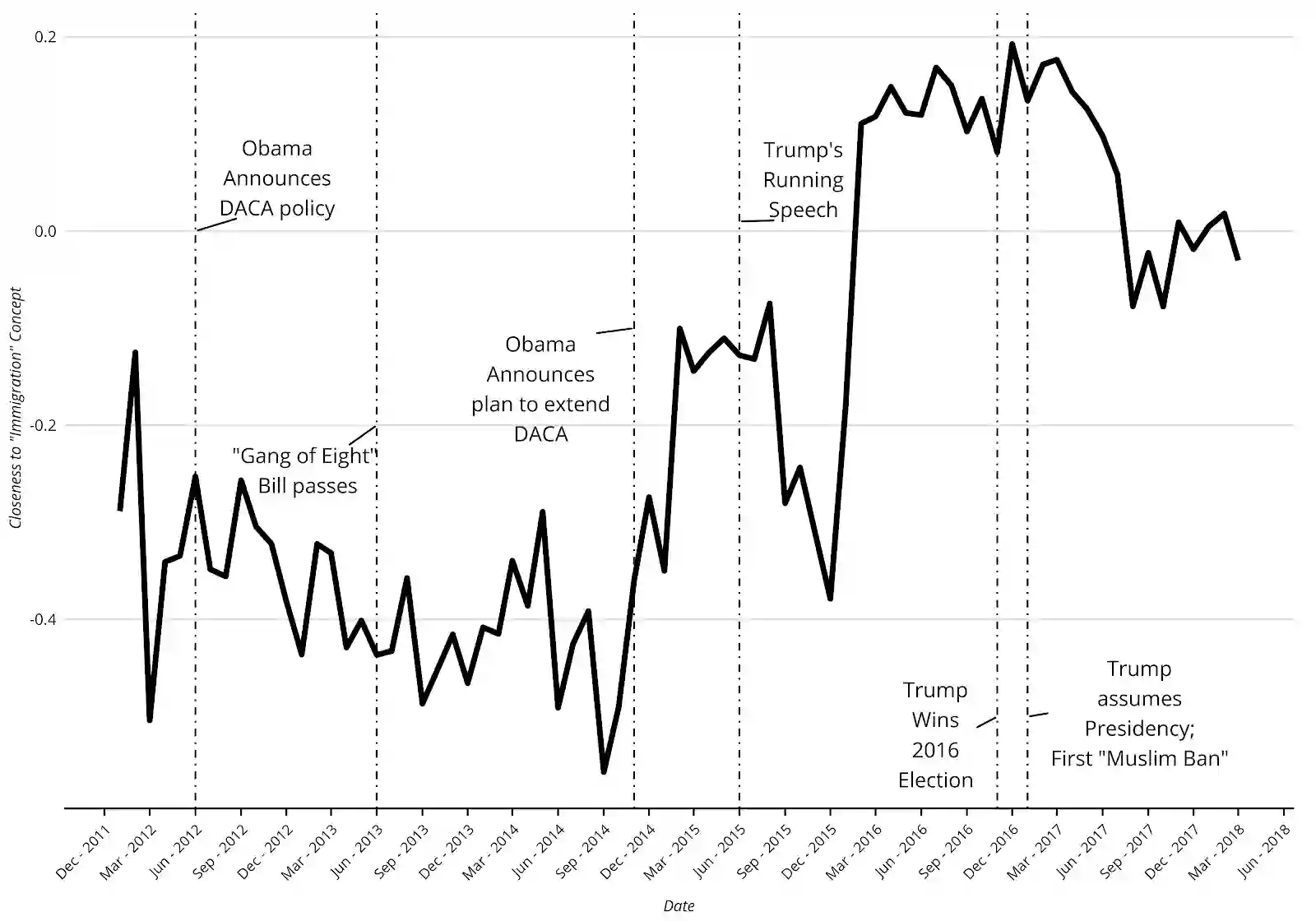
Using the frequency of keywords is a classic approach in the formal analysis of text, but has the drawback of glossing over the relationality of word meanings. Word embedding models overcome this problem by constructing a standardized and continuous "meaning-space" where words are assigned a location based on relations of similarity to other words based on how they are used in natural language samples. We show how word embeddings are commensurate with prevailing theories of meaning in sociology and can be put to the task of interpretation via two kinds of navigation. First, one can hold terms constant and measure how the embedding space moves around them -- much like astronomers measured the changing of celestial bodies with the seasons. Second, one can also hold the embedding space constant and see how documents or authors move relative to it -- just as ships use the stars on a given night to determine their location. Using the empirical case of immigration discourse in the United States, we demonstrate the merits of these two broad strategies for advancing important topics in cultural theory, including social marking, media fields, echo chambers, and cultural diffusion and change more broadly.
翻译:使用关键词的频率是正式分析文本的经典方法,但对于字义含义的关联性来说,使用关键词的频率是一个典型的方法,但有一个缺点,就是模糊了字义含义的关联性。字嵌入模型通过构建一个标准化和连续的“意思空间”克服了这个问题,在这个空间里,根据语言在自然语言样本中使用的方式,对词的相似性与其它词的关系分配一个位置。我们展示了字嵌入如何与社会学中普遍存在的意义理论相对应,并且可以通过两种导航方式被赋予解释任务。首先,人们可以保持术语不变,并测量嵌入空间在它们周围如何移动,就像天文学家测量天体随着季节的变化。第二,人们还可以保持嵌入空间常数,看看文件或作者如何相对地移动。正如船舶在特定夜晚利用恒星确定其位置一样,我们利用美国移民讨论的经验案例,展示了这两种广泛的战略在推动文化理论的重要课题方面的好处,包括社会标记、媒体领域、回声室以及文化传播和更广泛的变化。