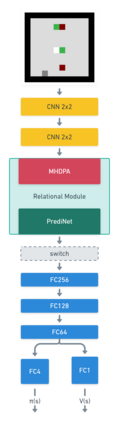
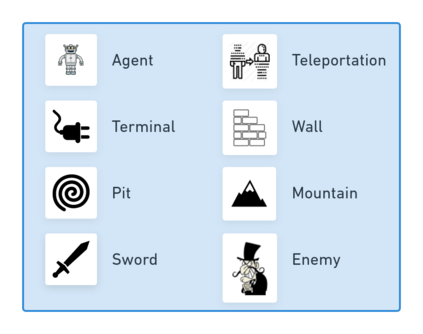
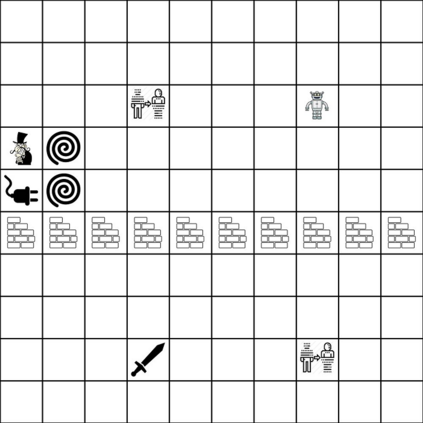
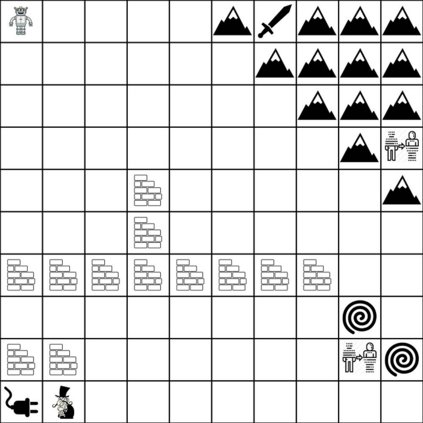
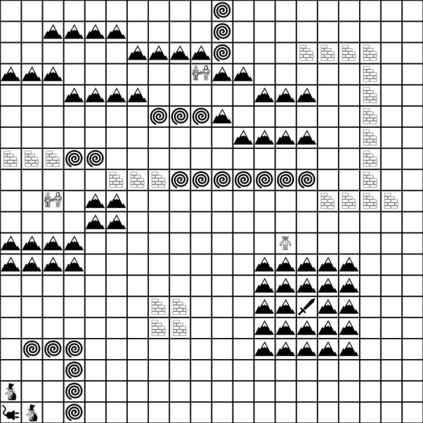
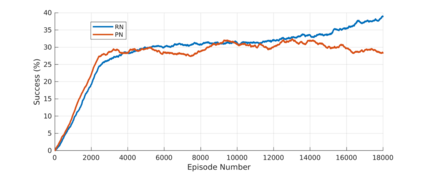
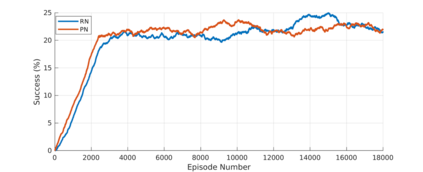
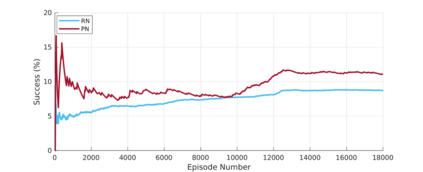
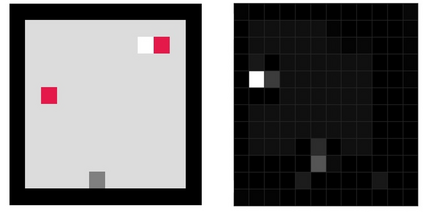
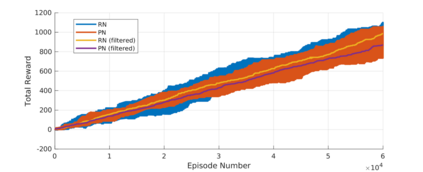
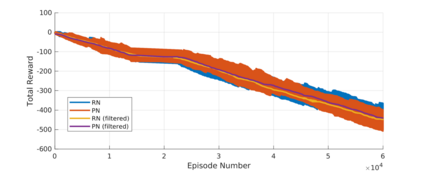
Reinforcement learning (RL) agents are often designed specifically for a particular problem and they generally have uninterpretable working processes. Statistical methods-based agent algorithms can be improved in terms of generalizability and interpretability using symbolic Artificial Intelligence (AI) tools such as logic programming. In this study, we present a model-free RL architecture that is supported with explicit relational representations of the environmental objects. For the first time, we use the PrediNet network architecture in a dynamic decision-making problem rather than image-based tasks, and Multi-Head Dot-Product Attention Network (MHDPA) as a baseline for performance comparisons. We tested two networks in two environments ---i.e., the baseline Box-World environment and our novel environment, Relational-Grid-World (RGW). With the procedurally generated RGW environment, which is complex in terms of visual perceptions and combinatorial selections, it is easy to measure the relational representation performance of the RL agents. The experiments were carried out using different configurations of the environment so that the presented module and the environment were compared with the baselines. We reached similar policy optimization performance results with the PrediNet architecture and MHDPA; additionally, we achieved to extract the propositional representation explicitly ---which makes the agent's statistical policy logic more interpretable and tractable. This flexibility in the agent's policy provides convenience for designing non-task-specific agent architectures. The main contributions of this study are two-fold ---an RL agent that can explicitly perform relational reasoning, and a new environment that measures the relational reasoning capabilities of RL agents.
翻译:强化学习(RL)代理商通常专门为某个特定问题设计,它们通常有无法解释的工作程序。基于统计方法的代理商算法可以使用逻辑编程等象征性人工智能(AI)工具改进通用性和可解释性。在本研究中,我们提出了一个无模型的RL架构,该架构得到环境对象明确关联性描述的支持。我们第一次使用PrediNet网络架构,这是一个动态决策问题,而不是基于图像的任务,多头多功能-促进关注网络(MHDPA)作为业绩比较的基准。我们在两种环境中测试了两个网络 -- 即基准箱-世界环境和我们新的环境环境环境环境环境(Rll-Grid-World)工具。我们用程序生成的 RGB环境环境环境(RW)环境(在视觉认识和组合选择方面是复杂的,很容易测量RL代理商的关联性表现。 实验采用不同的环境配置,以便所展示的模块和环境(MHDR) 明确进行新的结构(RHAL) 和(R)主要代理商的逻辑性对比,我们实现了类似的政策解释性(RHDPA) 和(M) 工具(BRA) 实现更多的政策结构(M) 和(M) 和(S) ) 模型(SIR) 实现更多的政策结构(S) 和(S) 和(S) ) 基础(S) ) (BI) (BR) (S) ) (BL) (SL) (S) (S) (SL) (SL) (SL) (PL) (L) (L) (P) (P) (L) (L) (L) (L) (L) (L) (L) (P) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L) (L)