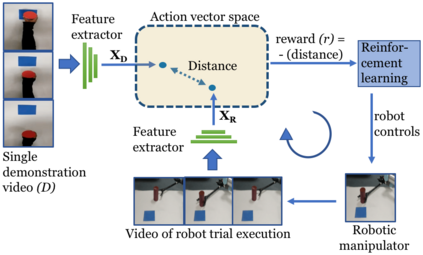
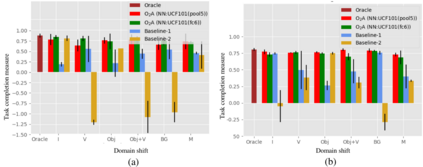
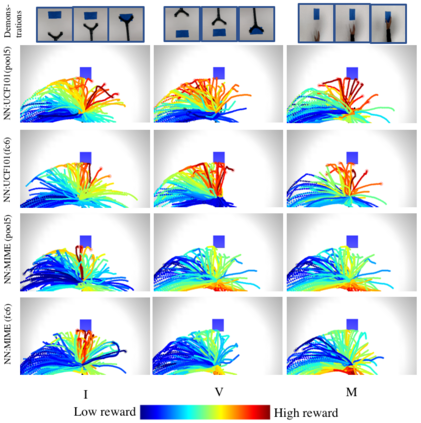
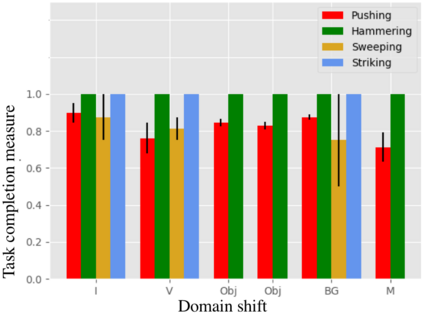
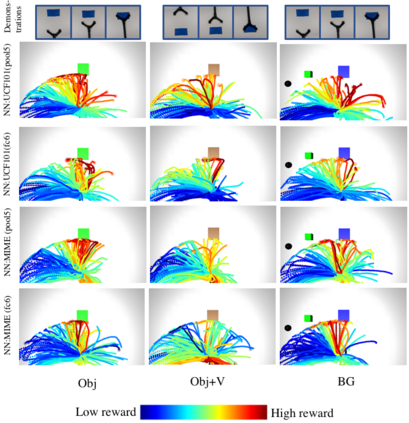
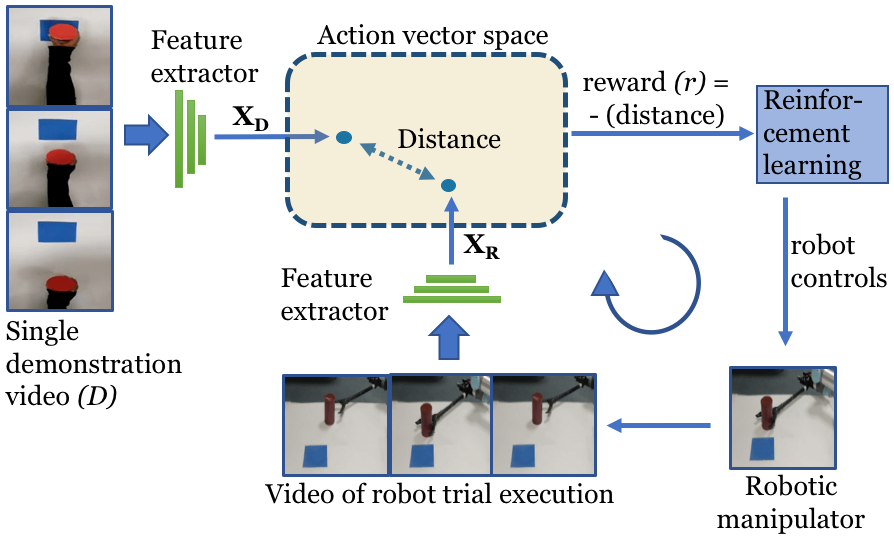
We present O2A, a novel method for learning to perform robotic manipulation tasks from a single (one-shot) third-person demonstration video. To our knowledge, it is the first time this has been done for a single demonstration. The key novelty lies in pre-training a feature extractor for creating a perceptual representation for actions that we call 'action vectors'. The action vectors are extracted using a 3D-CNN model pre-trained as an action classifier on a generic action dataset. The distance between the action vectors from the observed third-person demonstration and trial robot executions is used as a reward for reinforcement learning of the demonstrated task. We report on experiments in simulation and on a real robot, with changes in viewpoint of observation, properties of the objects involved, scene background and morphology of the manipulator between the demonstration and the learning domains. O2A outperforms baseline approaches under different domain shifts and has comparable performance with an oracle (that uses an ideal reward function).
翻译:我们从一个单一的(一发)第三人演示录像中展示了O2A,这是学习执行机器人操纵任务的一种新颖方法。 据我们所知,这是第一次对一个演示进行这样的演示。关键的新颖之处在于对一个为我们称之为“动作矢量”的行动创建概念性代表器进行预培训。动作矢量的提取使用了3D-CNN模型,这是在通用动作数据集上作为行动分类员预先训练过的。观察到的第三人演示和试验机器人处决的动作矢量之间的距离被用来作为奖励,以加强对所展示的任务的学习。我们报告模拟实验和真正的机器人实验,在观察角度、所涉物体特性、场景背景和操控者形态方面的变化,在演示和学习领域之间。O2A在不同的领域变化下优于基线方法,其性能与甲骨文(使用理想的奖励功能)相似。