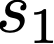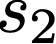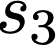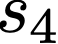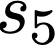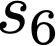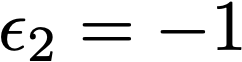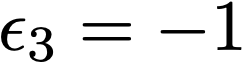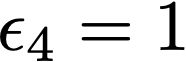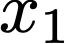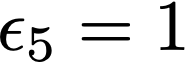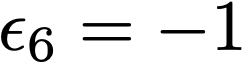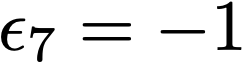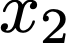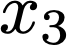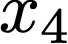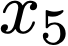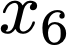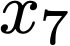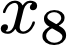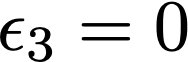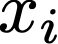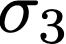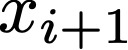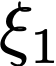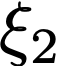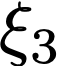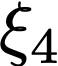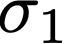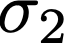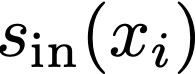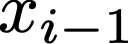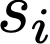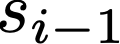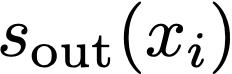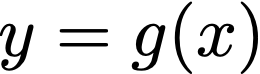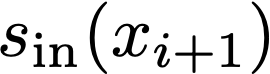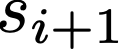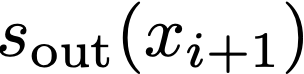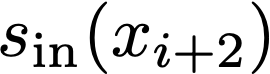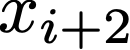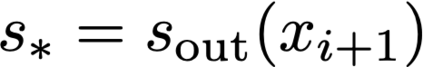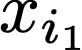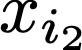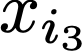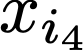We prove a precise geometric description of all one layer ReLU networks $z(x;\theta)$ with a single linear unit and input/output dimensions equal to one that interpolate a given dataset $\mathcal D=\{(x_i,f(x_i))\}$ and, among all such interpolants, minimize the $\ell_2$-norm of the neuron weights. Such networks can intuitively be thought of as those that minimize the mean-squared error over $\mathcal D$ plus an infinitesimal weight decay penalty. We therefore refer to them as ridgeless ReLU interpolants. Our description proves that, to extrapolate values $z(x;\theta)$ for inputs $x\in (x_i,x_{i+1})$ lying between two consecutive datapoints, a ridgeless ReLU interpolant simply compares the signs of the discrete estimates for the curvature of $f$ at $x_i$ and $x_{i+1}$ derived from the dataset $\mathcal D$. If the curvature estimates at $x_i$ and $x_{i+1}$ have different signs, then $z(x;\theta)$ must be linear on $(x_i,x_{i+1})$. If in contrast the curvature estimates at $x_i$ and $x_{i+1}$ are both positive (resp. negative), then $z(x;\theta)$ is convex (resp. concave) on $(x_i,x_{i+1})$. Our results show that ridgeless ReLU interpolants achieve the best possible generalization for learning $1d$ Lipschitz functions, up to universal constants.
翻译:我们证明了所有一层ReLU 网络的精确几何描述 $z( x;\theta) $1 美元( mathal D$ ) 和 无限重量腐蚀罚款。 因此,我们把它们称为无脊椎 ReLU 内部估计值。 我们的说明证明,对于输入的外推值$z( x_ i, f( x_ i)) $( x) 美元( x) 和在所有这些内推体中, 将神经重量的值最小化$( ell_ 2美元- norm) 。 这些网络可以直观地认为是那些将平均差差差差值降到$( mathal) D$( max) 和 $( $x) 内推值( 美元) 内算值( 美元) 和 美元内推值( 美元) 内推值( 美元) 内推值( 美元) 内推值( 美元) 内推值( 美元) 内算为 美元内算 美元内算 美元内算 美元 美元 。