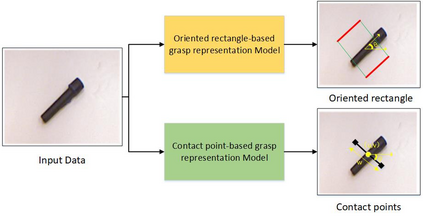
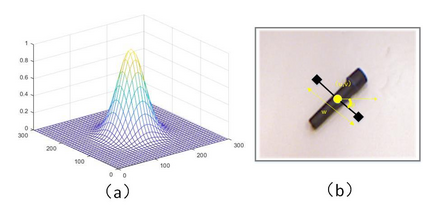
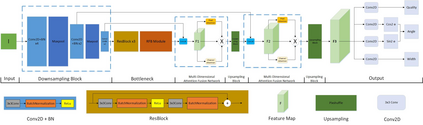
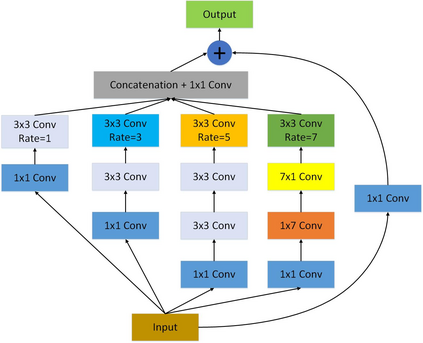
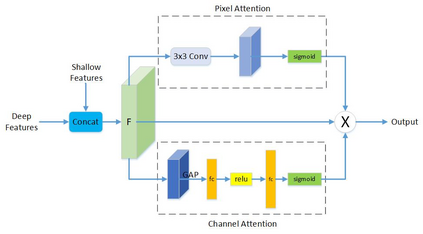
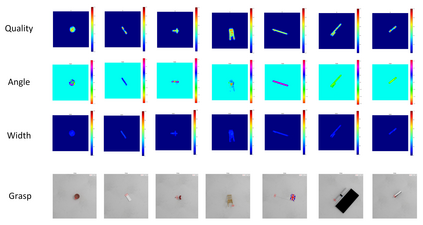
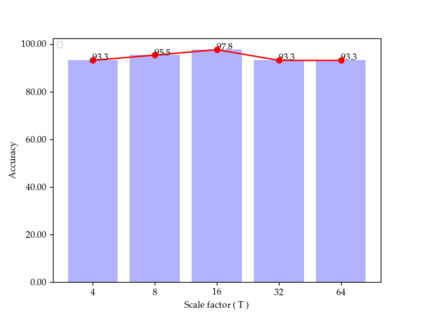
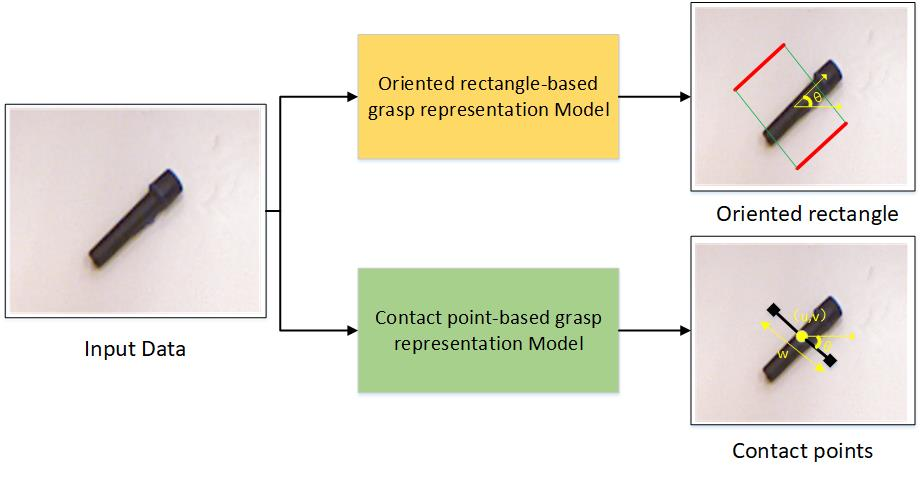
The method of deep learning has achieved excellent results in improving the performance of robotic grasping detection. However, the deep learning methods used in general object detection are not suitable for robotic grasping detection. Current modern object detectors are difficult to strike a balance between high accuracy and fast inference speed. In this paper, we present an efficient and robust fully convolutional neural network model to perform robotic grasping pose estimation from an n-channel input image of the real grasping scene. The proposed network is a lightweight generative architecture for grasping detection in one stage. Specifically, a grasping representation based on Gaussian kernel is introduced to encode training samples, which embodies the principle of maximum central point grasping confidence. Meanwhile, to extract multi-scale information and enhance the feature discriminability, a receptive field block (RFB) is assembled to the bottleneck of our grasping detection architecture. Besides, pixel attention and channel attention are combined to automatically learn to focus on fusing context information of varying shapes and sizes by suppressing the noise feature and highlighting the grasping object feature. Extensive experiments on two public grasping datasets, Cornell and Jacquard demonstrate the state-of-the-art performance of our method in balancing accuracy and inference speed. The network is an order of magnitude smaller than other excellent algorithms while achieving better performance with an accuracy of 98.9$\%$ and 95.6$\%$ on the Cornell and Jacquard datasets, respectively.
翻译:深层学习方法在改进机器人捕捉探测的性能方面取得了极好的成果;然而,一般物体探测所用的深层学习方法不适合机器人捕捉探测;目前现代物体探测器很难在高精度和快速推断速度之间取得平衡;在本文中,我们展示了一个高效和强大的全进化神经网络模型,以便从真实捕捉场的N通道输入图像中进行机器人捕捉估计;拟议网络是一个在某一阶段捕捉探测的轻量化结构。具体地说,根据高斯内核探测一般物体探测所用的深层方法来编码训练样品,这体现了最大限度中央点捕捉信心的原则。与此同时,要提取多级信息,提高特征的可辨别性,一个可接受的场块(RFB)将机器人捕捉到我们捕捉探测结构的瓶颈。此外,像素关注和通道的结合,通过抑制噪音特征和突出握取握取的物体特征,对美元。