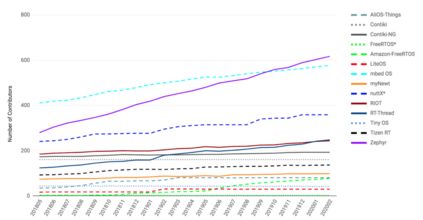
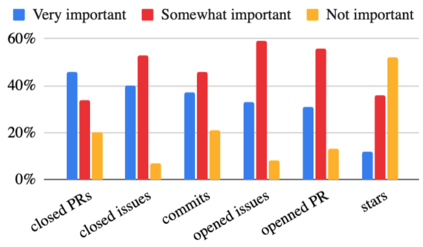
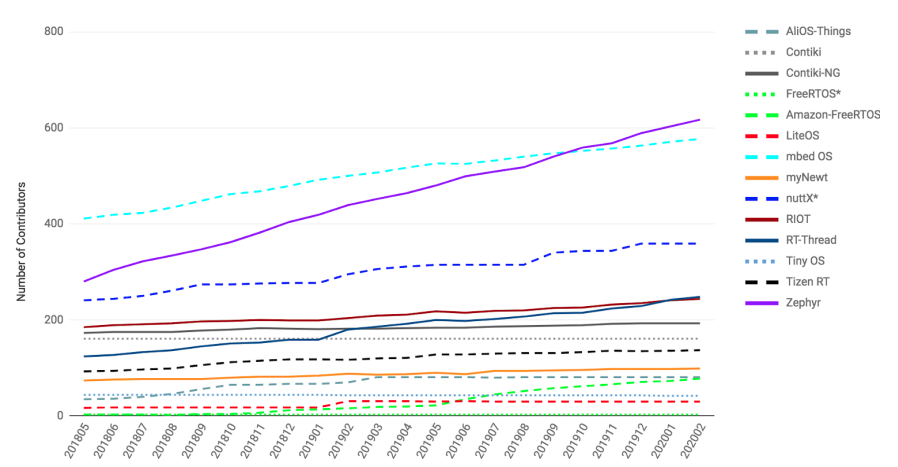
When data is scarce, software analytics can make many mistakes. For example, consider learning predictors for open source project health (e.g. the number of closed pull requests in twelve months time). The training data for this task may be very small (e.g. five years of data, collected every month means just 60 rows of training data). The models generated from such tiny data sets can make many prediction errors. Those errors can be tamed by a {\em landscape analysis} that selects better learner control parameters. Our niSNEAK tool (a)~clusters the data to find the general landscape of the hyperparameters; then (b)~explores a few representatives from each part of that landscape. niSNEAK is both faster and more effective than prior state-of-the-art hyperparameter optimization algorithms (e.g. FLASH, HYPEROPT, OPTUNA). The configurations found by niSNEAK have far less error than other methods. For example, for project health indicators such as $C$= number of commits; $I$=number of closed issues, and $R$=number of closed pull requests, niSNEAK's 12 month prediction errors are \{I=0\%, R=33\%\,C=47\%\} Based on the above, we recommend landscape analytics (e.g. niSNEAK) especially when learning from very small data sets. This paper only explores the application of niSNEAK to project health. That said, we see nothing in principle that prevents the application of this technique to a wider range of problems. To assist other researchers in repeating, improving, or even refuting our results, all our scripts and data are available on GitHub at https://github.com/zxcv123456qwe/niSneak
翻译:暂无翻译