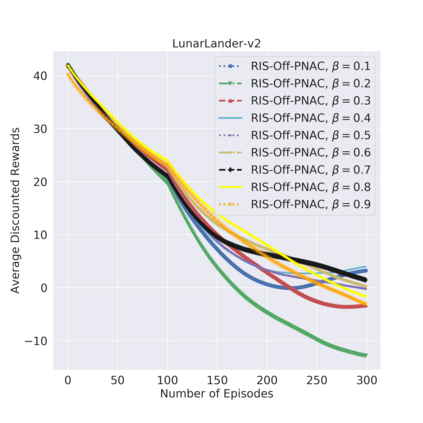
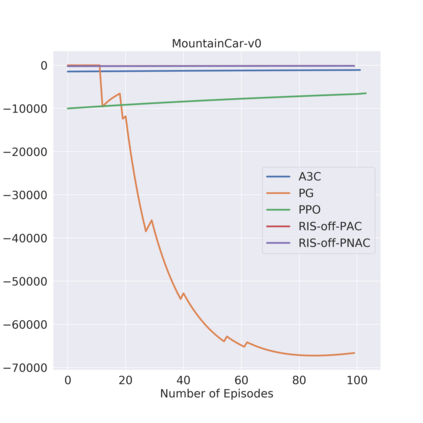
Off-policy learning is more unstable compared to on-policy learning in reinforcement learning (RL). One reason for the instability of off-policy learning is a discrepancy between the target ($\pi$) and behavior (b) policy distributions. The discrepancy between $\pi$ and b distributions can be alleviated by employing a smooth variant of the importance sampling (IS), such as the relative importance sampling (RIS). RIS has parameter $\beta\in[0, 1]$ which controls smoothness. To cope with instability, we present the first relative importance sampling-off-policy actor-critic (RIS-Off-PAC) model-free algorithms in RL. In our method, the network yields a target policy (the actor), a value function (the critic) assessing the current policy ($\pi$) using samples drawn from behavior policy. We use action value generated from the behavior policy in reward function to train our algorithm rather than from the target policy. We also use deep neural networks to train both actor and critic. We evaluated our algorithm on a number of Open AI Gym benchmark problems and demonstrate better or comparable performance to several state-of-the-art RL baselines.
翻译:与强化学习的政策性学习相比,非政策性学习更加不稳定。 政策性学习不稳定的原因之一是目标($pi$)与行为(b)政策分布之间的差异。 使用重要性抽样(IS)的平稳变量(RIS),例如相对重要性抽样(RIS),可以缓解美元和b分布之间的差异。RIS拥有控制平稳的参数$\beta\in[0,1]美元。为了应对不稳定性,我们在RL中展示了第一个相对重要的非政策性行为者-critic(RIS-off-critic(RIS-PAC)模型型算法。 在我们的方法中,网络产生一个目标政策(行为者),一个价值函数(批评家),用行为政策样本评估当前政策($\pi$),来评估当前政策的价值。我们用行为政策产生的行动价值来培训我们的算法,而不是目标性政策。我们还利用深神经网络来培训演员和评论家。 我们评估了我们关于公开AI Gym基准问题的一些算法,并展示好或可比的成绩。