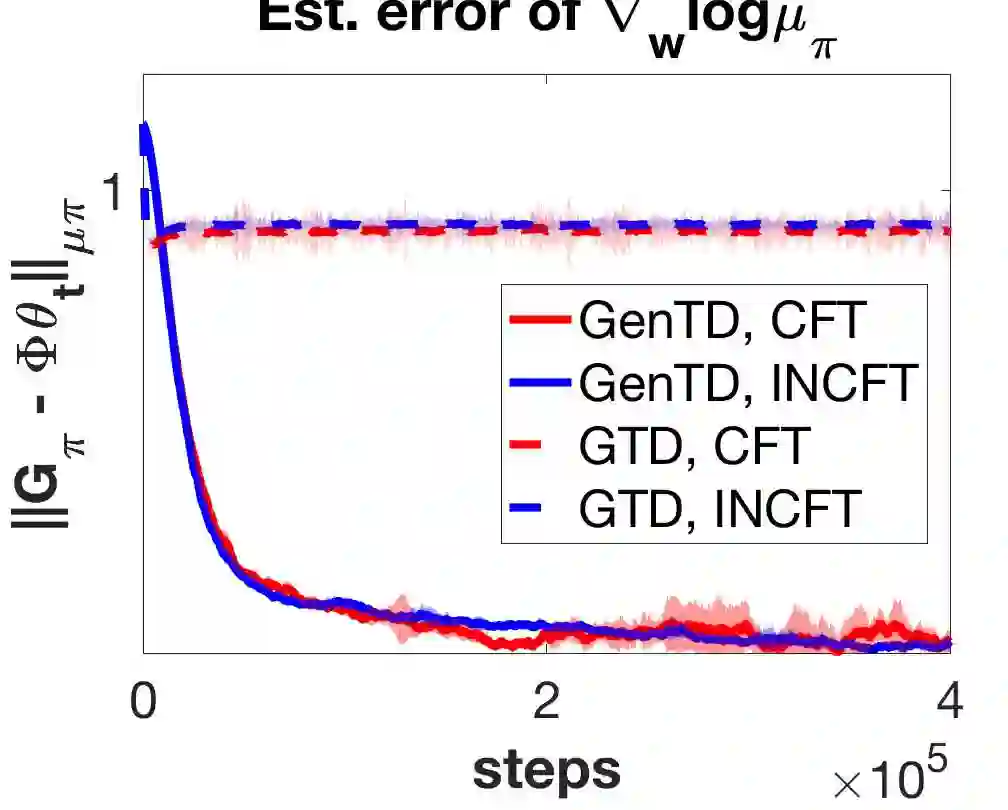
General Value Function (GVF) is a powerful tool to represent both the {\em predictive} and {\em retrospective} knowledge in reinforcement learning (RL). In practice, often multiple interrelated GVFs need to be evaluated jointly with pre-collected off-policy samples. In the literature, the gradient temporal difference (GTD) learning method has been adopted to evaluate GVFs in the off-policy setting, but such an approach may suffer from a large estimation error even if the function approximation class is sufficiently expressive. Moreover, none of the previous work have formally established the convergence guarantee to the ground truth GVFs under the function approximation settings. In this paper, we address both issues through the lens of a class of GVFs with causal filtering, which cover a wide range of RL applications such as reward variance, value gradient, cost in anomaly detection, stationary distribution gradient, etc. We propose a new algorithm called GenTD for off-policy GVFs evaluation and show that GenTD learns multiple interrelated multi-dimensional GVFs as efficiently as a single canonical scalar value function. We further show that unlike GTD, the learned GVFs by GenTD are guaranteed to converge to the ground truth GVFs as long as the function approximation power is sufficiently large. To our best knowledge, GenTD is the first off-policy GVF evaluation algorithm that has global optimality guarantee.
翻译:一般价值函数( GVF) 是代表 ~ em 预测 } 和 ~ 回溯 } 知识的强大工具, 在强化学习中代表 ~ 预测 和 ~ 回溯 。 实际上, 在实践上, 通常需要与预先收集的政策样本一起对多个相互关联的 GVF 进行联合评估。 在文献中, 采用了梯度时间差异( GTD) 学习方法来评估离政策环境中的 GVF, 但即使功能近似等级足够明确, 这种方法也可能受到重大估算错误的影响 。 此外, 先前的工作没有一个正式在函数近似设置下建立了与地面真理 GVF 的趋同保证 。 在本文中, 我们通过一个具有因果关系过滤功能的GVF 类 GVF 的透视镜来讨论这两个问题。 我们进一步证明GTD 与GVF 的极强的GV 直观功能相比, GVDF 已经充分保证了我们GV 最接近了全球的GV 。