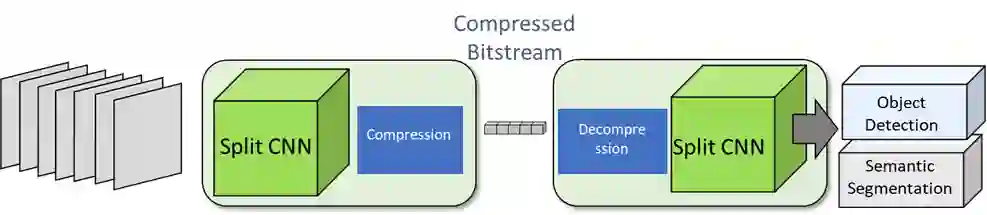
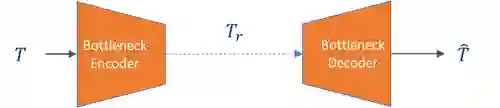
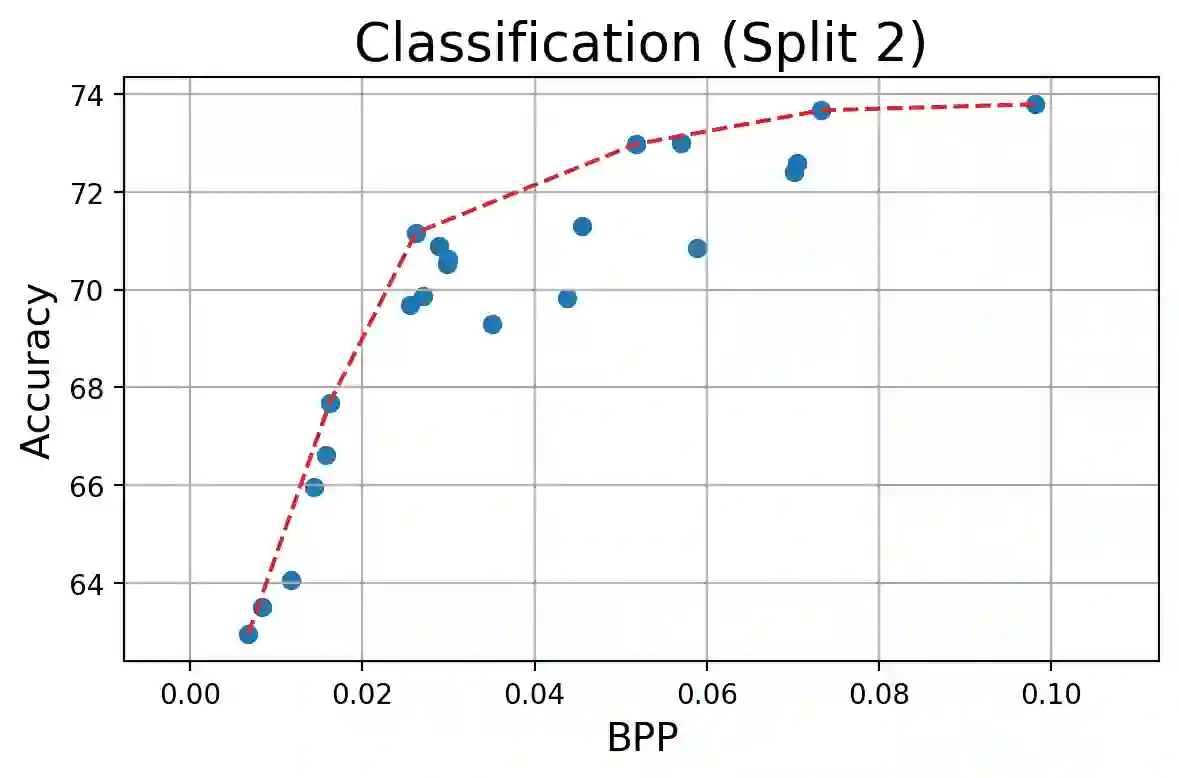
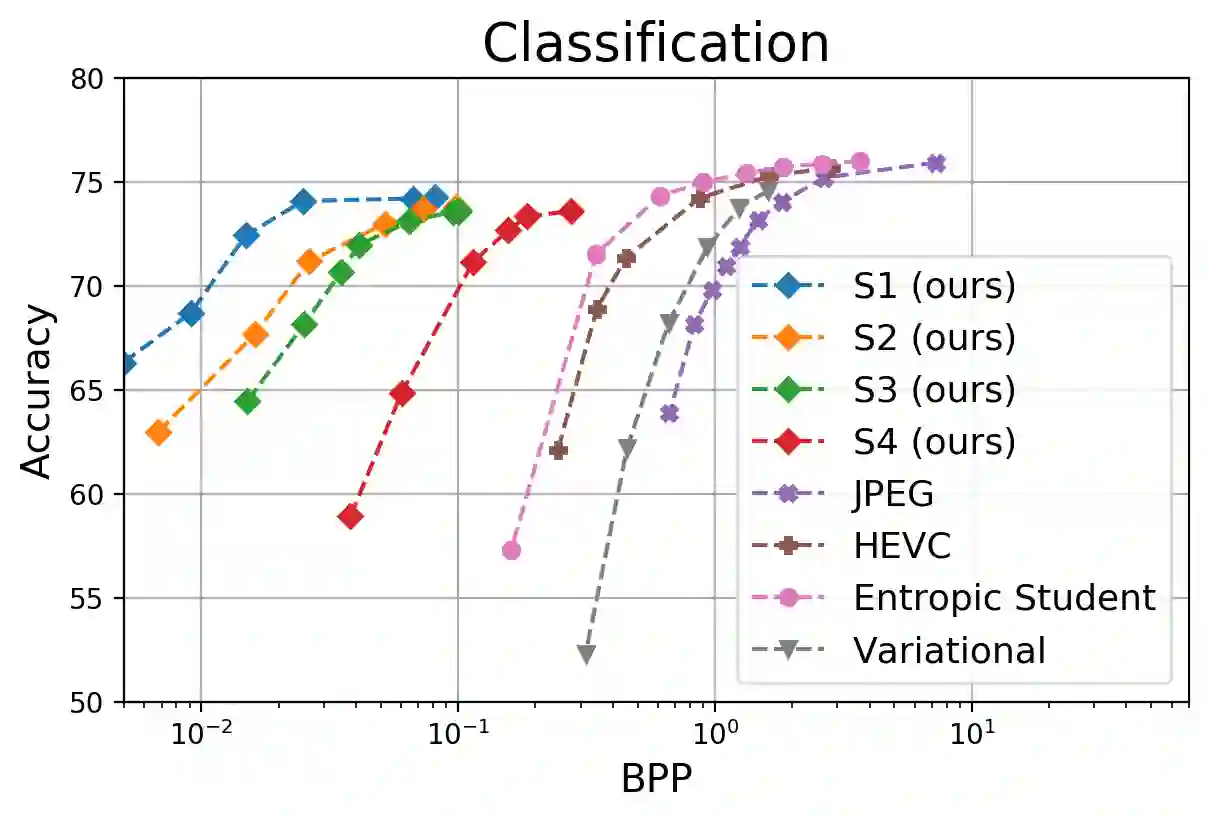
Split computing has emerged as a recent paradigm for implementation of DNN-based AI workloads, wherein a DNN model is split into two parts, one of which is executed on a mobile/client device and the other on an edge-server (or cloud). Data compression is applied to the intermediate tensor from the DNN that needs to be transmitted, addressing the challenge of optimizing the rate-accuracy-complexity trade-off. Existing split-computing approaches adopt ML-based data compression, but require that the parameters of either the entire DNN model, or a significant portion of it, be retrained for different compression levels. This incurs a high computational and storage burden: training a full DNN model from scratch is computationally demanding, maintaining multiple copies of the DNN parameters increases storage requirements, and switching the full set of weights during inference increases memory bandwidth. In this paper, we present an approach that addresses all these challenges. It involves the systematic design and training of bottleneck units - simple, low-cost neural networks - that can be inserted at the point of split. Our approach is remarkably lightweight, both during training and inference, highly effective and achieves excellent rate-distortion performance at a small fraction of the compute and storage overhead compared to existing methods.
翻译:分解计算是实施基于 DNN 的 AI 工作量的近期范例, 其中DNN 模型分为两个部分, 其中一个在移动/ 客户设备上执行, 另一个在边缘服务器( 或云) 上执行。 数据压缩适用于 DNN 需要传输的中点, 应对优化速率- 准确度- 兼容性交易的挑战。 现有的分解计算方法采用了基于 ML 的数据压缩, 但要求对整个 DNN 模型或其中相当一部分的参数进行不同压缩水平的再培训。 这造成了一个很高的计算和存储负担: 从零开始培训全 DNNN 模型在计算上要求很高, 保持多份 DNN 参数的存储要求, 并在推论增加记忆带宽时转换整套重量。 在本文中, 我们介绍了一种应对所有这些挑战的方法。 它涉及系统设计和培训瓶式单元( 简单、 低成本的神经网络) 的参数可以插入到分裂点。 这造成了一个很高的计算和存储负担: 从零到零的完全, 我们的方法具有极低的性, 和高压的存储率, 和高压 。