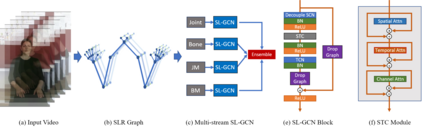
Sign language is used by deaf or speech impaired people to communicate and requires great effort to master. Sign Language Recognition (SLR) aims to bridge between sign language users and others by recognizing words from given videos. It is an important yet challenging task since sign language is performed with fast and complex movement of hand gestures, body posture, and even facial expressions. Recently, skeleton-based action recognition attracts increasing attention due to the independence on subject and background variation. Furthermore, it can be a strong complement to RGB/D modalities to boost the overall recognition rate. However, skeleton-based SLR is still under exploration due to the lack of annotations on hand keypoints. Some efforts have been made to use hand detectors with pose estimators to extract hand key points and learn to recognize sign language via a Recurrent Neural Network, but none of them outperforms RGB-based methods. To this end, we propose a novel Skeleton Aware Multi-modal SLR framework (SAM-SLR) to further improve the recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics and propose a novel Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. Our skeleton-based method achieves a higher recognition rate compared with all other single modalities. Moreover, our proposed SAM-SLR framework can further enhance the performance by assembling our skeleton-based method with other RGB and depth modalities. As a result, SAM-SLR achieves the highest performance in both RGB (98.42\%) and RGB-D (98.53\%) tracks in 2021 Looking at People Large Scale Signer Independent Isolated SLR Challenge. Our code is available at https://github.com/jackyjsy/CVPR21Chal-SLR
翻译:聋哑人或语言受损人使用手势语言进行沟通,需要大力掌握语言。手语识别(SLR)旨在通过识别特定视频中的文字在手语使用者和其他人之间架起桥梁。这是一个重要但具有挑战性的任务,因为手势、身体姿势、甚至面部表情的快速和复杂的移动是手势、身体姿势、甚至面部表情的动作。最近,由于在主题和背景差异上的独立性,基于骨架的行动识别吸引了越来越多的关注。此外,它可以成为对RGB/D模式的有力补充,以提高总体识别率。然而,基于骨架的SLRLR(S-PRD)由于手键点上缺乏说明,仍在探索基于骨架的SLRLR(S-C) 。已经做出一些努力,使用手动探测器来显示显示关键点,并学会通过一个最新的SGBS-S-R(S-RV) SLR(S-S-S-S-SLR) 动作框架(S-SL) 和S-SLS-S-SL(S-SL-S-S-S-SL-S-S-Sl-Sl-S-S-S-S-S-S-Sl-Sl-S-S-S-S-Sl-S-S-S-Sl-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-Sl-Sl-S-S-Sl-S-S-Sl-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-SL-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-