【CVPR2020】视频符号语言识别中跨领域知识的传递, Transferring Cross-domain Knowledge for Video Sign Language Recognition

主题: Transferring Cross-domain Knowledge for Video Sign Language Recognition
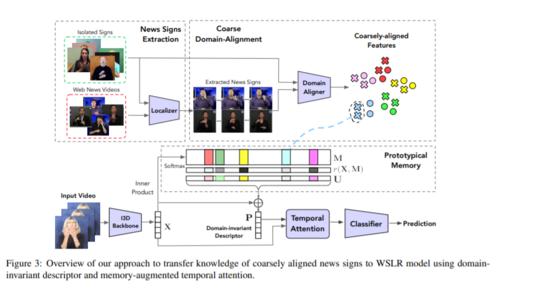
摘要: 单词级符号语言识别(WSLR)是符号语言解释中的一项基本任务。它需要模型来识别视频中孤立的标志词。但是,注释WSLR数据需要专业知识,因此限制了WSLR数据集的获取。相反,互联网上有大量带字幕的新闻新闻视频。由于这些视频没有单词级注释,并且与孤立的符号之间存在较大的领域差异,因此无法直接用于训练WSLR模型。我们观察到,尽管存在较大的领域差距,但独立的和新闻标语共享相同的视觉概念,例如手势和身体动作。受此观察结果的启发,我们提出了一种新颖的方法,该方法可学习领域不变的视觉概念,并通过将带字幕的新闻标志的知识传递给WSLR模型,学习领域不变的视觉概念,并使之丰富。为此,我们使用基本的WSLR模型提取新闻标志,然后设计一个联合训练的新闻和孤立标志分类器,以粗略地将这两个领域特征对齐。为了学习每个类别中的领域不变特征并抑制领域特定特征,我们的方法进一步求助于外部存储器来存储对齐的新闻标志的类别质心。然后,我们基于学习到的描述符设计时间注意力,以提高识别性能。在标准WSLR数据集上的实验结果表明,我们的方法明显优于以前的最新方法。我们还演示了该方法在自动定位路标新闻中的路标方面的有效性,AP @ 0.5达到28.1
成为VIP会员查看完整内容
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
38+阅读 · 2019年12月26日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关VIP内容
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
38+阅读 · 2019年12月26日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日