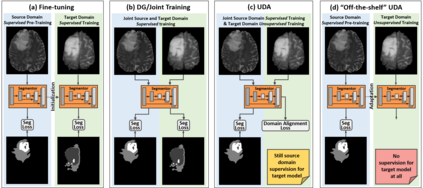
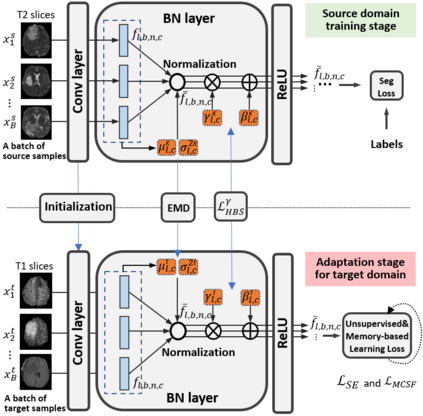
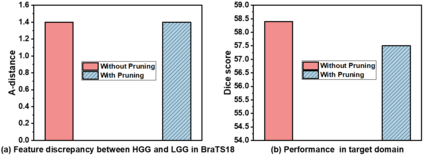
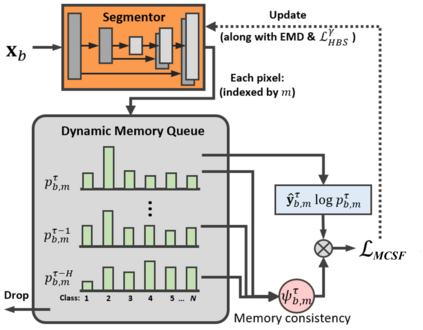
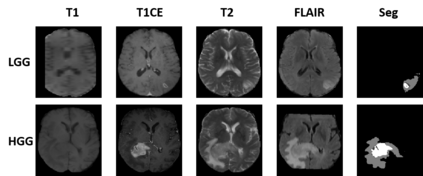
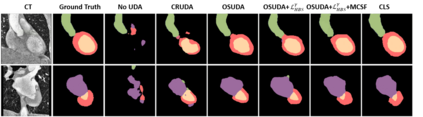
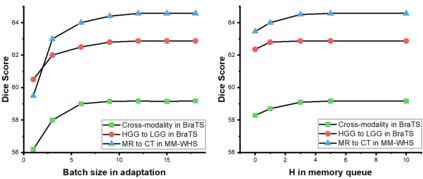
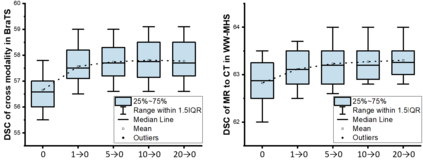
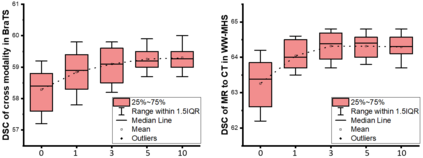
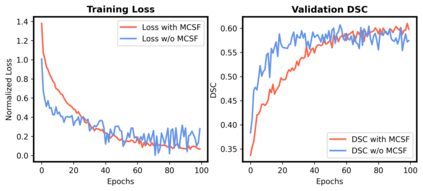
Unsupervised domain adaptation (UDA) has been a vital protocol for migrating information learned from a labeled source domain to facilitate the implementation in an unlabeled heterogeneous target domain. Although UDA is typically jointly trained on data from both domains, accessing the labeled source domain data is often restricted, due to concerns over patient data privacy or intellectual property. To sidestep this, we propose "off-the-shelf (OS)" UDA (OSUDA), aimed at image segmentation, by adapting an OS segmentor trained in a source domain to a target domain, in the absence of source domain data in adaptation. Toward this goal, we aim to develop a novel batch-wise normalization (BN) statistics adaptation framework. In particular, we gradually adapt the domain-specific low-order BN statistics, e.g., mean and variance, through an exponential momentum decay strategy, while explicitly enforcing the consistency of the domain shareable high-order BN statistics, e.g., scaling and shifting factors, via our optimization objective. We also adaptively quantify the channel-wise transferability to gauge the importance of each channel, via both low-order statistics divergence and a scaling factor.~Furthermore, we incorporate unsupervised self-entropy minimization into our framework to boost performance alongside a novel queued, memory-consistent self-training strategy to utilize the reliable pseudo label for stable and efficient unsupervised adaptation. We evaluated our OSUDA-based framework on both cross-modality and cross-subtype brain tumor segmentation and cardiac MR to CT segmentation tasks. Our experimental results showed that our memory consistent OSUDA performs better than existing source-relaxed UDA methods and yields similar performance to UDA methods with source data.
翻译:不受监督的域适应(UDA)一直是将从标签源域中获取的信息迁移到目标域的重要协议,以便利在无标签的杂交目标域内实施。尽管UDA通常在这两个域内的数据方面接受联合培训,但是由于对病人数据隐私或知识产权的关切,访问标签源域数据往往受到限制。为避免这种情况,我们提议通过在没有源域域域数据的情况下,将一个在源域内受过培训的OS部分调整为目标域,从而将信息迁移到一个目标域内,以便利在没有源域域域域内执行。为了实现这一目标,我们的目标是开发一个新型的批次正常(BN)数据调整框架。特别是,我们通过指数指数变异性BN统计,即平均值和差异,通过指数变异性(OSDA)战略,明确实施共享的高级BN统计数据的一致性,例如,通过我们的优化目标,缩放和变异性因素。我们通过适应性化的方式量化频道的可转移性,以衡量每个频道的重要性,通过低级(BNBBB)的递减(BB)的自动递减(O-LI)级数据框架,同时进行稳定的内存变的自我变换)的自我变换和升级的自我变换,同时进行我们的自我变换,将我们的自我演化的运行(OLI-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-deal-destr)的绩效)的运行法化的运行法化的运行法的运行法。