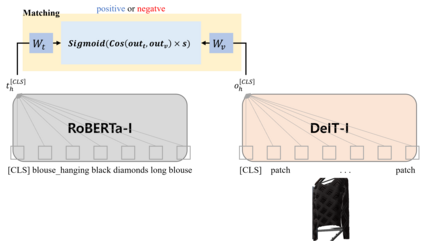
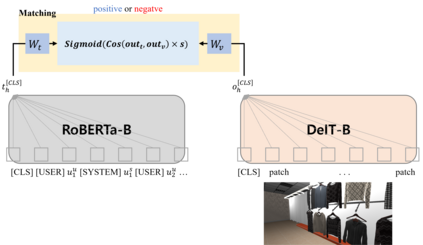
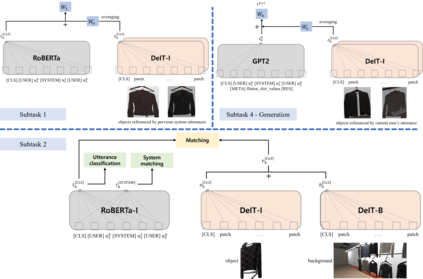
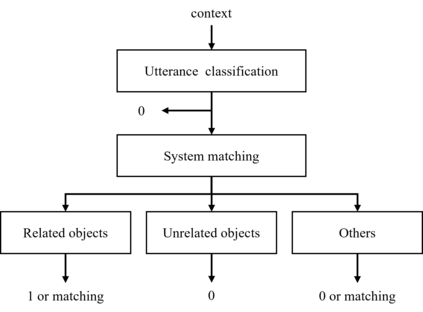
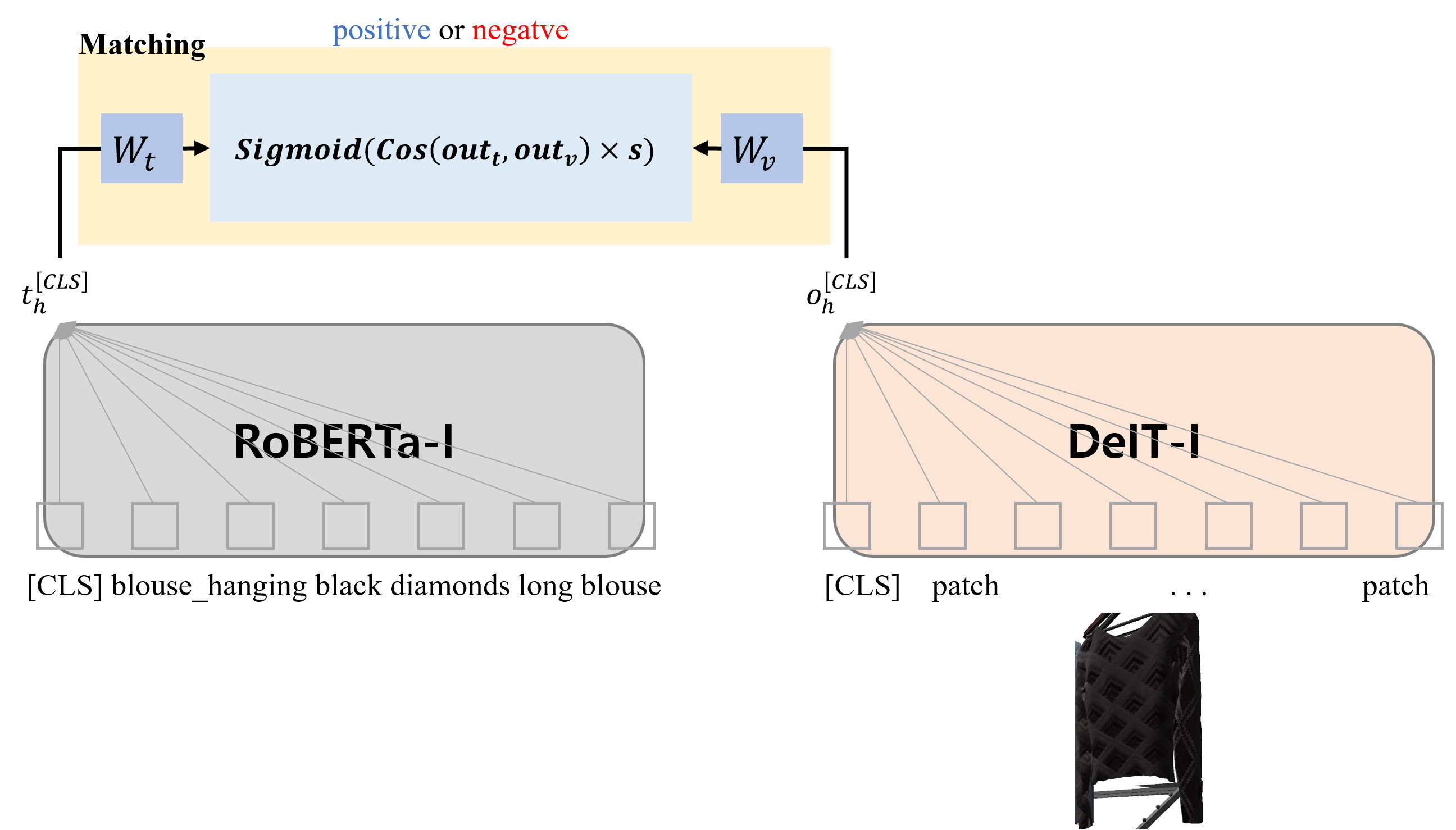
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
翻译:本文介绍我们在 " 对话国跟踪挑战10 " 中进行的关于 " 点点互动多式互动多式对话2.0挑战 " 的工作。 SIMMC 2. 0 包括4个子任务,我们为子任务+1, ⁇ 2和生成子任务+4. SIMMC 2. 0 数据集介绍了我们的多式方法。 SIMMC 2. 0 数据集是一个包含图像和文本信息的多式数据集,这比仅仅基于文本的对话问题更具挑战性,因为它必须通过理解图像和文本之间的关系来解决。因此,由于只解决像BERT或GPT2这样的文本模型是有限度的,我们建议采用一个将图像和文本相结合的多式模型。我们首先为多式模型预设了理解图像和文本之间关系的模式,然后对每一项任务进行微调。我们在子任务+1, ⁇ 2 和子任务+4. 的生成中取得了第三种最佳性能。源代码可在https://github.com/rungjoo/simmc2.0上查阅。