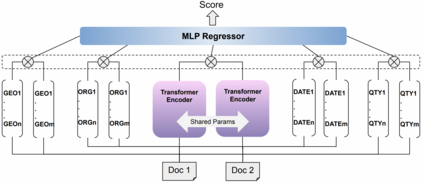
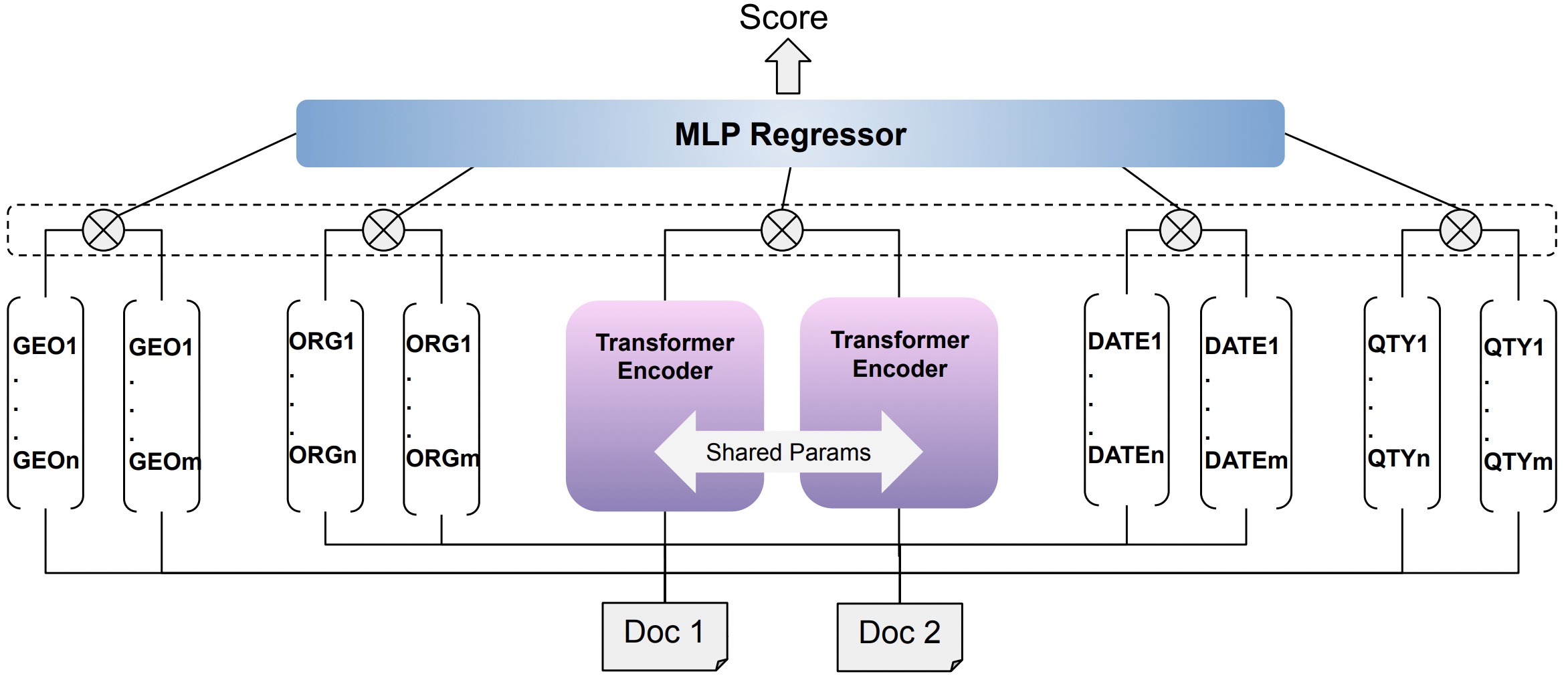
This paper describes the second-placed system on the leaderboard of SemEval-2022 Task 8: Multilingual News Article Similarity. We propose an entity-enriched Siamese Transformer which computes news article similarity based on different sub-dimensions, such as the shared narrative, entities, location and time of the event discussed in the news article. Our system exploits a Siamese network architecture using a Transformer encoder to learn document-level representations for the purpose of capturing the narrative together with the auxiliary entity-based features extracted from the news articles. The intuition behind using all these features together is to capture the similarity between news articles at different granularity levels and to assess the extent to which different news outlets write about "the same events". Our experimental results and detailed ablation study demonstrate the effectiveness and the validity of our proposed method.
翻译:本文描述了SemEval-2022任务8:多语种新闻文章相似性的领导板上的第二位系统。我们建议建立一个实体富集的暹罗变异器,根据不同次分类计算新闻文章相似性,如新闻报道中讨论的事件的共同叙事、实体、地点和时间。我们的系统利用一个暹罗网络结构,利用一个变换编码器来学习文件层面的表述,以便与从新闻文章中提取的辅助实体特征一起捕捉叙述。所有这些特征背后的直觉是捕捉不同颗粒级的新闻文章之间的相似性,并评估不同新闻媒体撰写“相同事件”的程度。我们的实验结果和详细的缩写研究显示了我们拟议方法的有效性和有效性。