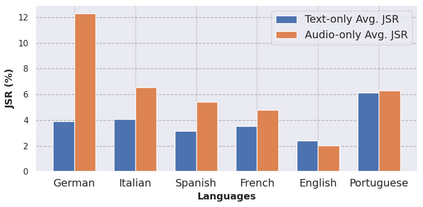
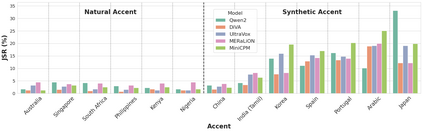
Large Audio Language Models (LALMs) have significantly advanced audio understanding but introduce critical security risks, particularly through audio jailbreaks. While prior work has focused on English-centric attacks, we expose a far more severe vulnerability: adversarial multilingual and multi-accent audio jailbreaks, where linguistic and acoustic variations dramatically amplify attack success. In this paper, we introduce Multi-AudioJail, the first systematic framework to exploit these vulnerabilities through (1) a novel dataset of adversarially perturbed multilingual/multi-accent audio jailbreaking prompts, and (2) a hierarchical evaluation pipeline revealing that how acoustic perturbations (e.g., reverberation, echo, and whisper effects) interacts with cross-lingual phonetics to cause jailbreak success rates (JSRs) to surge by up to +57.25 percentage points (e.g., reverberated Kenyan-accented attack on MERaLiON). Crucially, our work further reveals that multimodal LLMs are inherently more vulnerable than unimodal systems: attackers need only exploit the weakest link (e.g., non-English audio inputs) to compromise the entire model, which we empirically show by multilingual audio-only attacks achieving 3.1x higher success rates than text-only attacks. We plan to release our dataset to spur research into cross-modal defenses, urging the community to address this expanding attack surface in multimodality as LALMs evolve.
翻译:暂无翻译