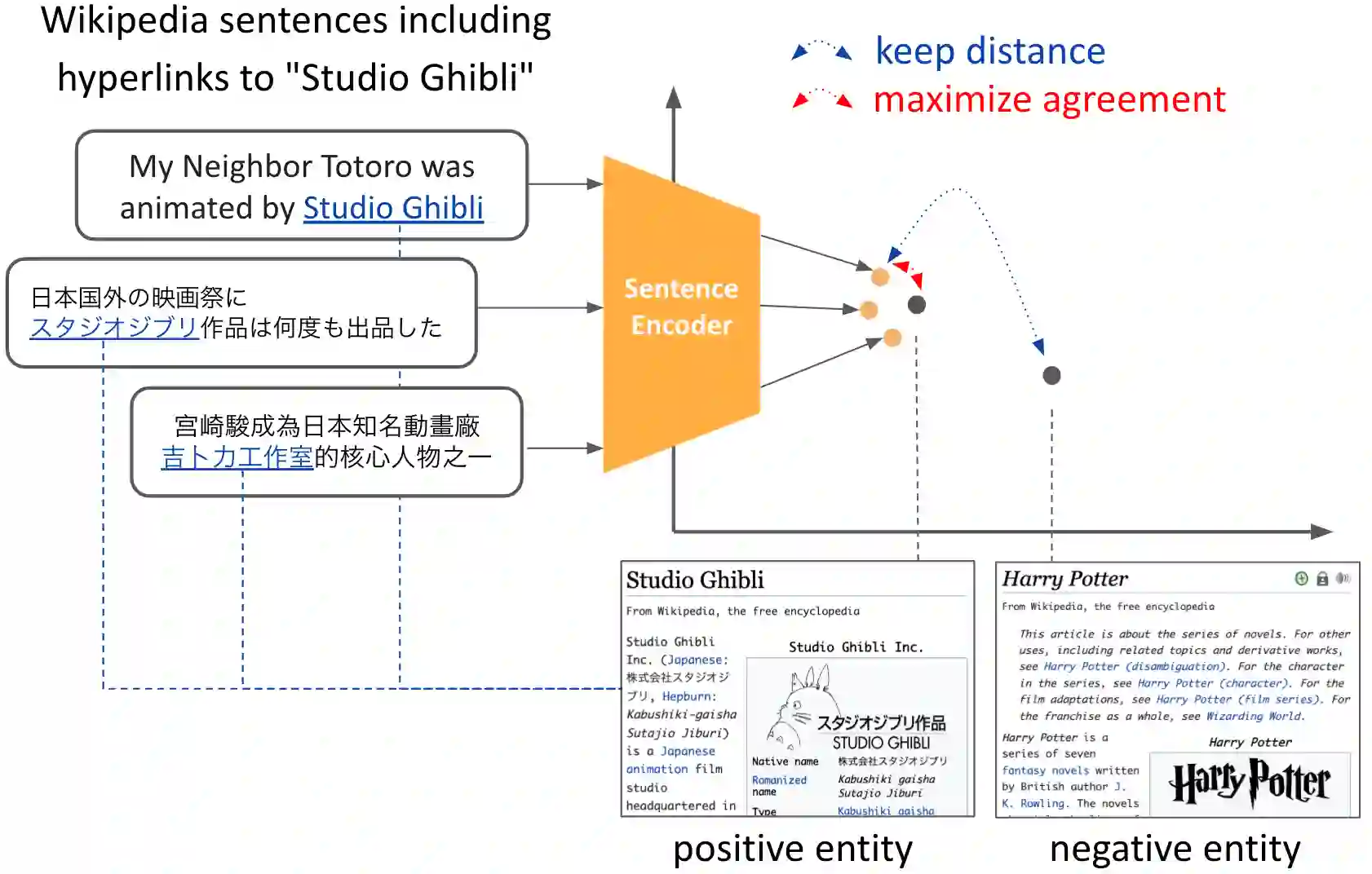
We present EASE, a novel method for learning sentence embeddings via contrastive learning between sentences and their related entities. The advantage of using entity supervision is twofold: (1) entities have been shown to be a strong indicator of text semantics and thus should provide rich training signals for sentence embeddings; (2) entities are defined independently of languages and thus offer useful cross-lingual alignment supervision. We evaluate EASE against other unsupervised models both in monolingual and multilingual settings. We show that EASE exhibits competitive or better performance in English semantic textual similarity (STS) and short text clustering (STC) tasks and it significantly outperforms baseline methods in multilingual settings on a variety of tasks. Our source code, pre-trained models, and newly constructed multilingual STC dataset are available at https://github.com/studio-ousia/ease.
翻译:我们提出EASE,这是通过对判决及其相关实体的对比性学习而嵌入判决的一种新颖方法,使用实体监督的好处有两个方面:(1) 实体已证明是文字语义的有力指标,因此应当为判决嵌入提供丰富的培训信号;(2) 实体的定义独立于语言,从而提供有用的跨语言协调监督;我们对照单一语言和多语言环境中其他不受监督的模式,对EASE进行评估;我们表明,EASE在英语语义文本相似性和短文本组别(STS)任务中表现出竞争性或更好的表现,在多种任务中大大优于多语种环境中的基线方法。我们的源代码、预先培训的模式和新建的多语种STC数据集可在https://github.com/studio-ousia/sease查阅。