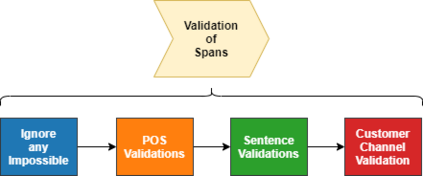
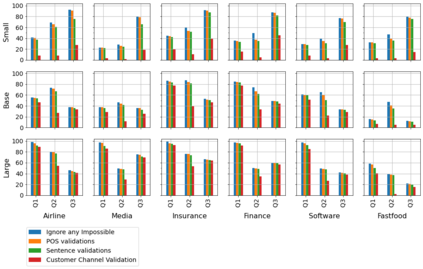
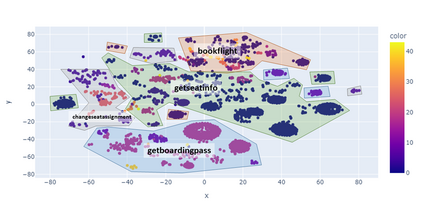
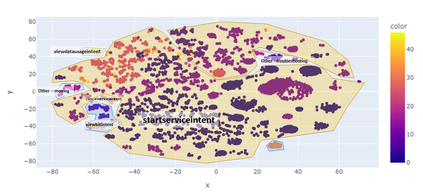
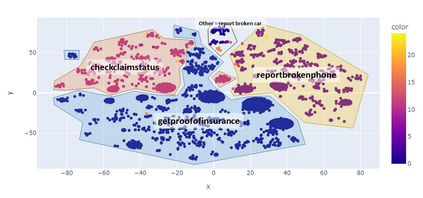
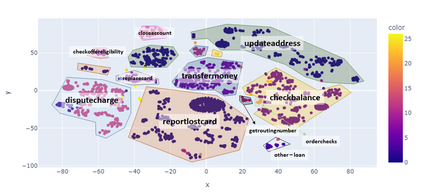
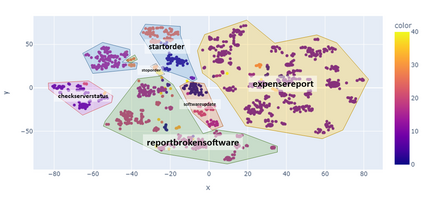
For companies with customer service, mapping intents inside their conversational data is crucial in building applications based on natural language understanding (NLU). Nevertheless, there is no established automated technique to gather the intents from noisy online chats or voice transcripts. Simple clustering approaches are not suited to intent-sparse dialogues. To solve this intent-landscape task, we propose an unsupervised pipeline that extracts the intents and the taxonomy of intents from real-world dialogues. Our pipeline mines intent-span candidates with an extractive Question-Answering Electra model and leverages sentence embeddings to apply a low-level density clustering followed by a top-level hierarchical clustering. Our results demonstrate the generalization ability of an ELECTRA large model fine-tuned on the SQuAD2 dataset to understand dialogues. With the right prompting question, this model achieves a rate of linguistic validation on intent spans beyond 85%. We furthermore reconstructed the intent schemes of five domains from the MultiDoGo dataset with an average recall of 94.3%.
翻译:对于有客户服务的公司来说,在建立基于自然语言理解(NLU)的应用程序时,对谈话数据中的意图进行绘图至关重要。然而,没有固定的自动化技术来收集来自吵闹的在线聊天或语音记录誊本的意向。简单的集群方法不适合意向扭曲的对话。为了解决这一意向景观任务,我们建议建立一个不受监督的管道,从现实世界对话中提取意图和意图分类。我们的管道式地雷意图分布候选人,其开采式问题解答 Electra模型和杠杆句嵌入,以应用低密度集群,然后采用最高等级的等级集群。我们的结果表明,在SQuAD2数据集上对ELECTRA大型模型进行精细调整以了解对话的通用能力。在正确的问题下,该模型在意向方面实现了语言验证率超过85%。我们还从多多多戈多功能数据集中将五个域的意向方案重新组合,平均回收了94.3%。