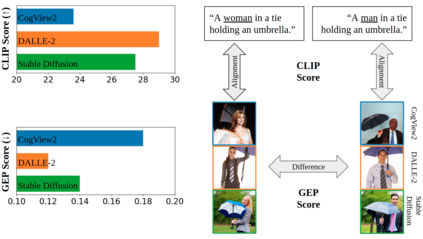
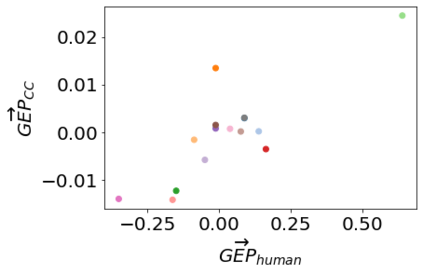
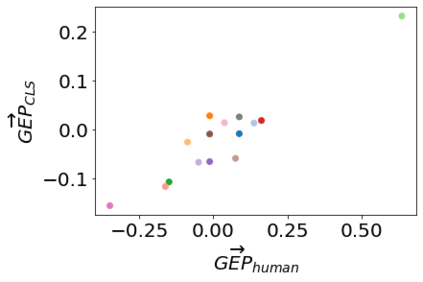
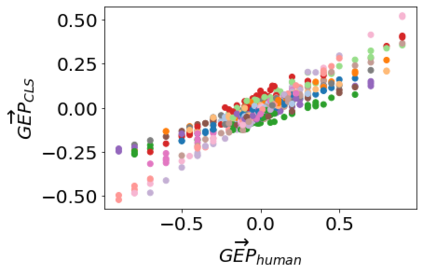
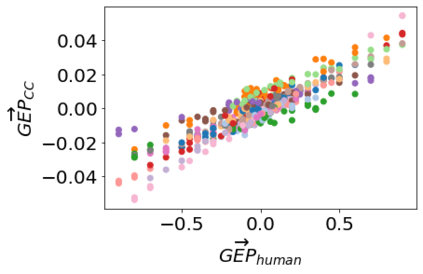
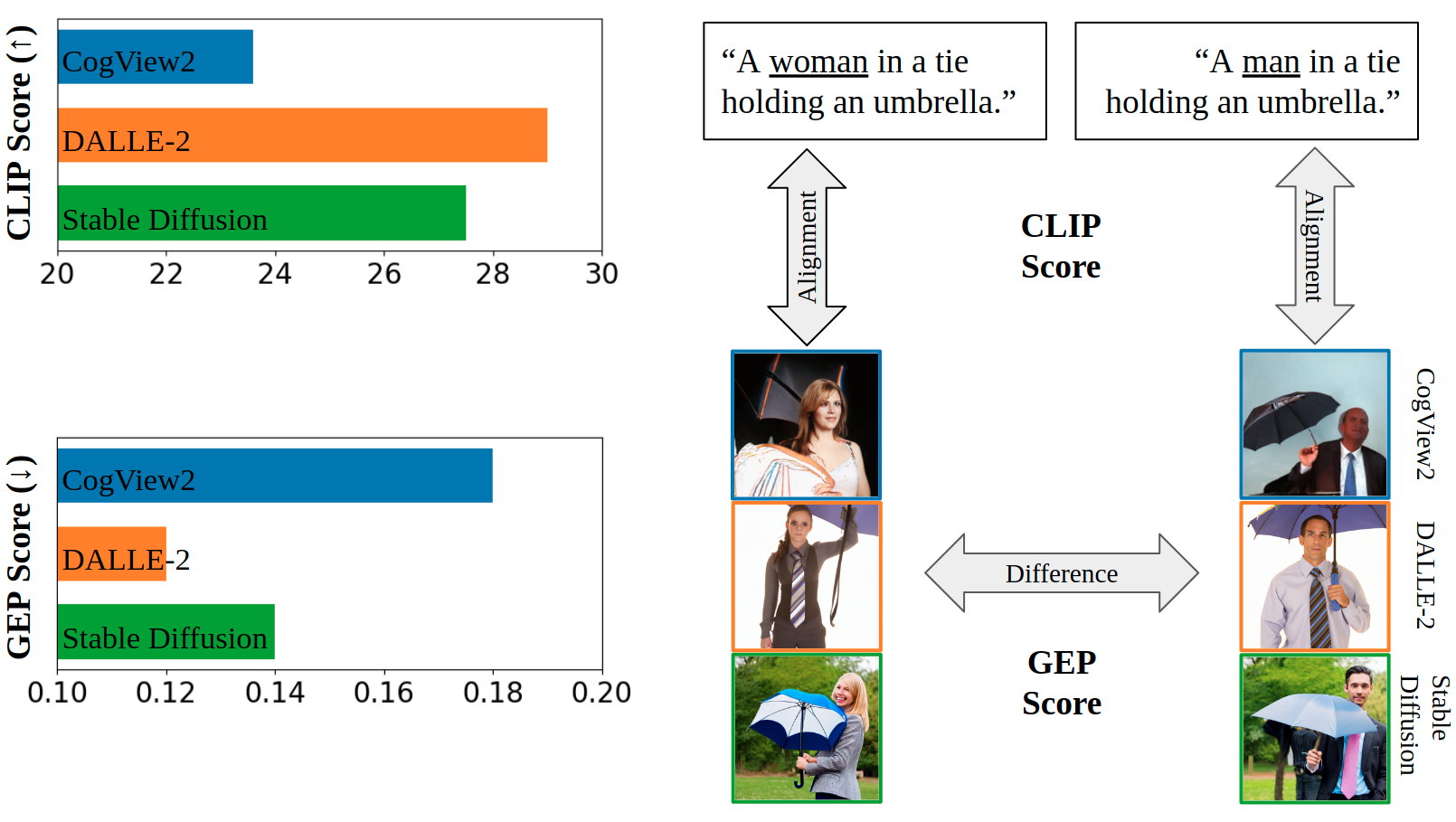
Text-to-image models, which can generate high-quality images based on textual input, have recently enabled various content-creation tools. Despite significantly affecting a wide range of downstream applications, the distributions of these generated images are still not fully understood, especially when it comes to the potential stereotypical attributes of different genders. In this work, we propose a paradigm (Gender Presentation Differences) that utilizes fine-grained self-presentation attributes to study how gender is presented differently in text-to-image models. By probing gender indicators in the input text (e.g., "a woman" or "a man"), we quantify the frequency differences of presentation-centric attributes (e.g., "a shirt" and "a dress") through human annotation and introduce a novel metric: GEP. Furthermore, we propose an automatic method to estimate such differences. The automatic GEP metric based on our approach yields a higher correlation with human annotations than that based on existing CLIP scores, consistently across three state-of-the-art text-to-image models. Finally, we demonstrate the generalization ability of our metrics in the context of gender stereotypes related to occupations.
翻译:文本到图像模型可以产生基于文字输入的高质量图像,这些模型最近使各种内容生成工具成为了各种内容生成工具。尽管这些生成图像的分布对下游应用产生了显著影响,但仍然不能完全理解,特别是对于不同性别潜在的陈规定型特征而言。在这项工作中,我们提出了一个范例(性别展示差异),利用微小的自我展示属性来研究文本到图像模型中性别的表述方式如何不同。我们通过在输入文本中(例如“女性”或“男性”)对性别指标进行验证,我们通过人文注解来量化展示中心特征(例如“衬衫”和“服装”)的频率差异,并采用新的衡量标准:GEP。此外,我们提出了一种自动方法来估计这种差异。基于我们的方法的自动GEP指标与人文说明的相关性高于基于现有的CLIP分数,这始终贯穿三个最先进的文本到图像模型。最后,我们展示了我们在与性别陈规定型观念有关的职业方面的衡量标准的普遍化能力。