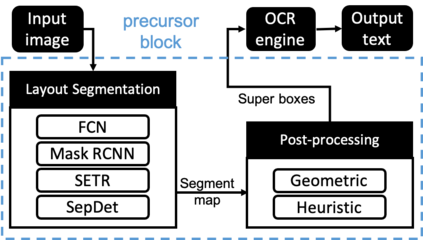
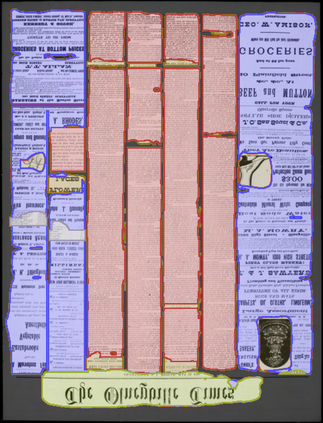
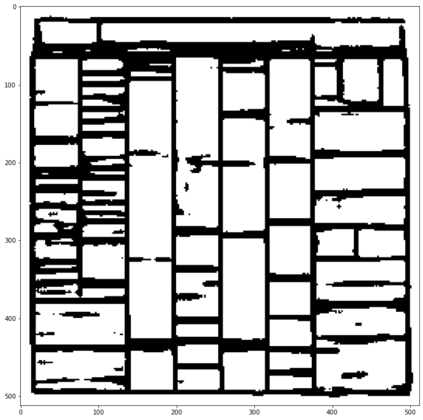
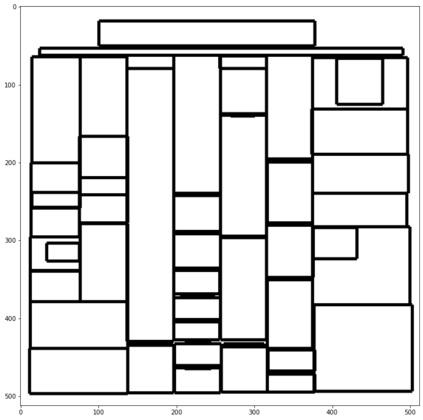
Digitization of newspapers is of interest for many reasons including preservation of history, accessibility and search ability, etc. While digitization of documents such as scientific articles and magazines is prevalent in literature, one of the main challenges for digitization of newspaper lies in its complex layout (e.g. articles spanning multiple columns, text interrupted by images) analysis, which is necessary to preserve human read-order. This work provides a major breakthrough in the digitization of newspapers on three fronts: first, releasing a dataset of 3000 fully-annotated, real-world newspaper images from 21 different U.S. states representing an extensive variety of complex layouts for document layout analysis; second, proposing layout segmentation as a precursor to existing optical character recognition (OCR) engines, where multiple state-of-the-art image segmentation models and several post-processing methods are explored for document layout segmentation; third, providing a thorough and structured evaluation protocol for isolated layout segmentation and end-to-end OCR.
翻译:由于保存历史、无障碍和搜索能力等许多原因,报纸的数字化很有意义。 虽然科学文章和杂志等文件的数字化在文献中很普遍,但报纸数字化的主要挑战之一在于其复杂的布局分析(例如,横跨多栏的文章,文字被图像打断),这是维护人类阅读秩序所必需的。这项工作在报纸数字化的三个方面提供了一个重大突破:第一,公布21个美国不同国家的3000个全注、真实世界报纸图像数据集,这些数据集代表了文件布局分析的多种多样的复杂布局;第二,提议将布局分割作为现有光学字符识别引擎的先导,其中为文件布局分割探索了多种最先进的图像分割模型和若干处理后方法;第三,为孤立的布局分割和端端对端的 OCR提供了彻底和结构化的评价协议。