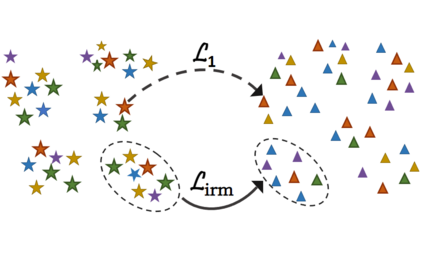
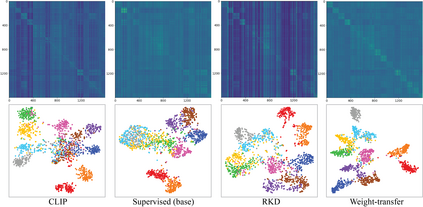
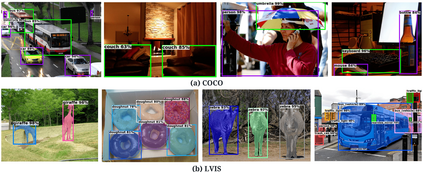
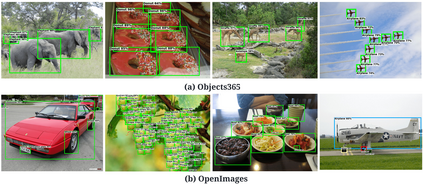
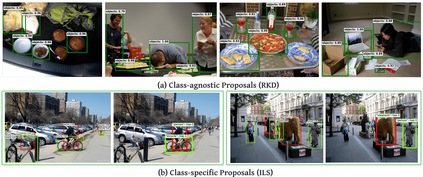
Existing open-vocabulary object detectors typically enlarge their vocabulary sizes by leveraging different forms of weak supervision. This helps generalize to novel objects at inference. Two popular forms of weak-supervision used in open-vocabulary detection (OVD) include pretrained CLIP model and image-level supervision. We note that both these modes of supervision are not optimally aligned for the detection task: CLIP is trained with image-text pairs and lacks precise localization of objects while the image-level supervision has been used with heuristics that do not accurately specify local object regions. In this work, we propose to address this problem by performing object-centric alignment of the language embeddings from the CLIP model. Furthermore, we visually ground the objects with only image-level supervision using a pseudo-labeling process that provides high-quality object proposals and helps expand the vocabulary during training. We establish a bridge between the above two object-alignment strategies via a novel weight transfer function that aggregates their complimentary strengths. In essence, the proposed model seeks to minimize the gap between object and image-centric representations in the OVD setting. On the COCO benchmark, our proposed approach achieves 40.3 AP50 on novel classes, an absolute 11.9 gain over the previous best performance.For LVIS, we surpass the state-of-the-art ViLD model by 5.0 mask AP for rare categories and 3.4 overall. Code: https://bit.ly/3byZoQp.
翻译:现有的开放词汇对象探测器通常通过利用不同形式的薄弱监督来扩大其词汇规模。 这有助于对推断中的新对象进行概括化。 两种开放词汇探测中使用的受欢迎的弱监督模式包括预先培训的CLIP模型和图像级监督。 我们注意到,这两种监督模式都与探测任务没有最佳的一致: CLIP 使用图像- 文本配对培训,缺乏对对象的精确本地化,而图像级监督则使用不准确指定当地目标区域的超常性能监督。 在这项工作中,我们建议通过对CLIP 模型中嵌入的语言进行以对象为中心的对齐来解决这一问题。 此外,我们用一个假标签程序来对仅对图像级监督对象进行视觉化定位,提供高质量的物体建议,并帮助扩大培训期间的词汇。 我们通过一种新颖的重力转换功能,将上述两个对象的定位战略连接起来。 实质上, 拟议的模型试图通过对目标对象和VI- CD 3 进行对象和图像中心在CLIP 模式中进行目标- 3 嵌入式的定位。 在前一个绝对水平 AL- RDS 上, 我们的C- ISO- greal- grealeval- glection- LS as agal becal be as as as as as level level level as