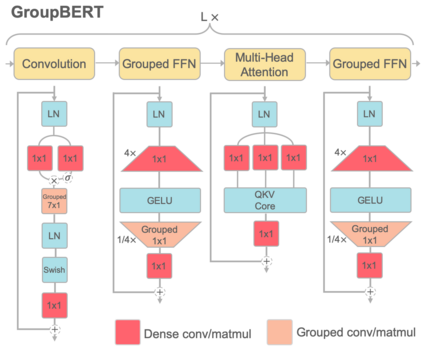
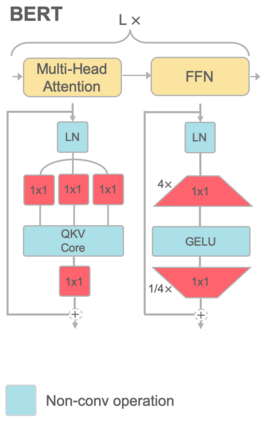
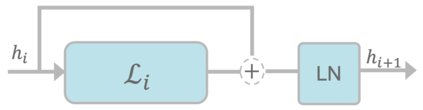
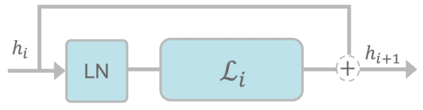
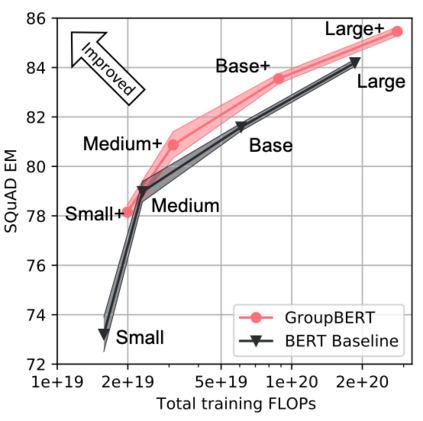
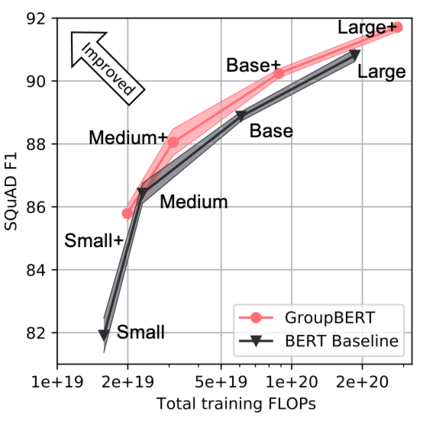
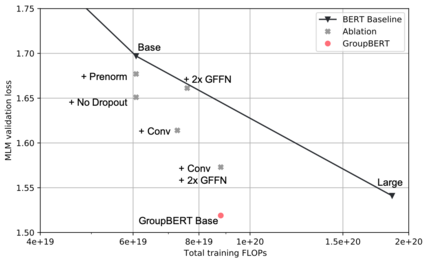
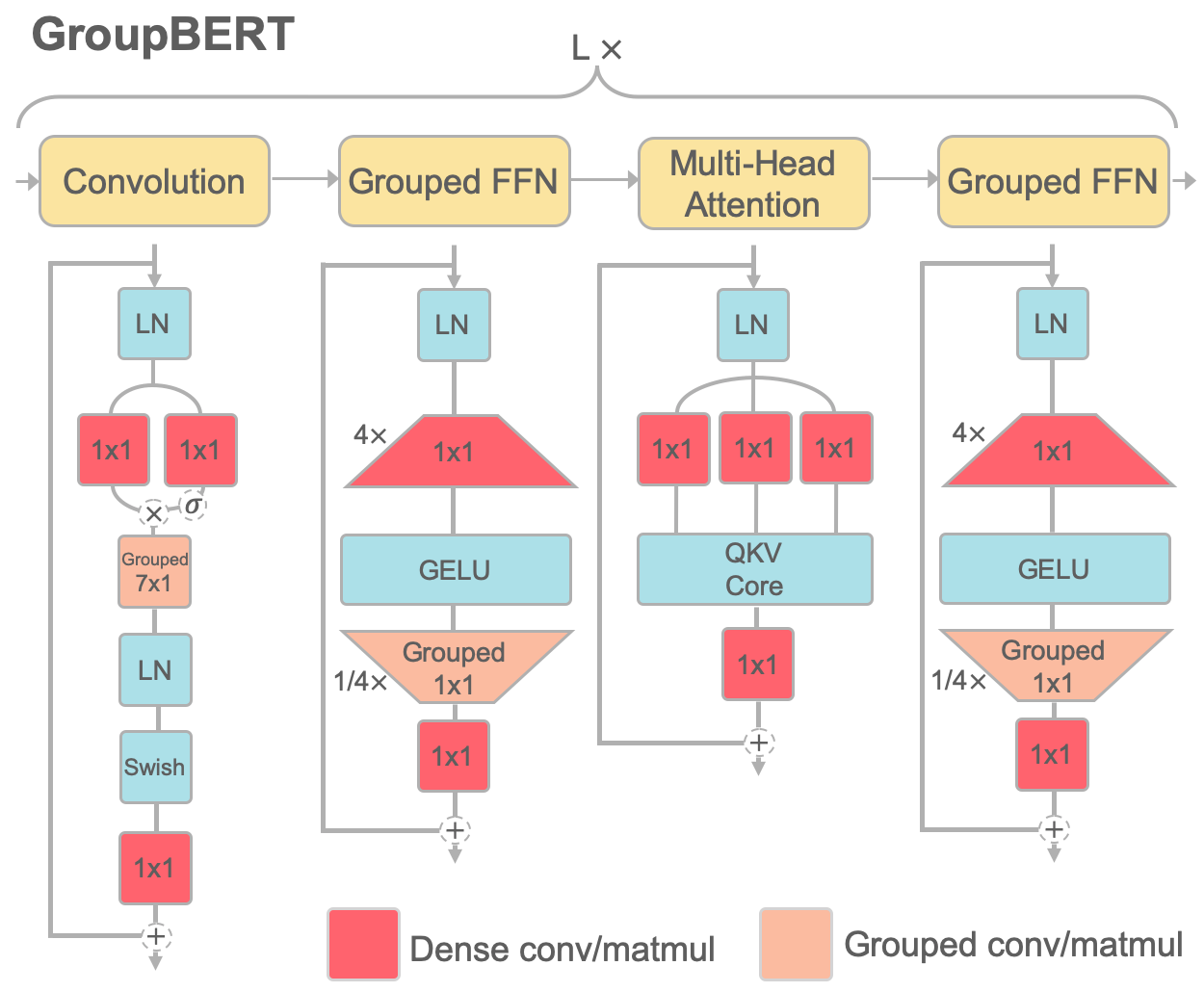
Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.
翻译:以关注为基础的语言模型已成为最先进的自然语言处理系统的一个关键组成部分,然而,这些模型由于培训时间长、操作密度大、参数计数大,具有重要的计算要求。在这项工作中,我们展示了对变异层结构的一套修改,产生了一种效率更高的结构。首先,我们增加了一个革命模块,以补充自省模块,使当地和全球互动的学习脱钩。第二,我们依靠组合式转换来降低密集进料层和进料层的计算成本,同时保持模型的清晰度。我们将由此产生的结构用于语言代表学习,并展示其优于不同尺度的BERT模型的性能。我们进一步强调其效率的提高,包括浮点操作(FLOPs)和时间对时间。