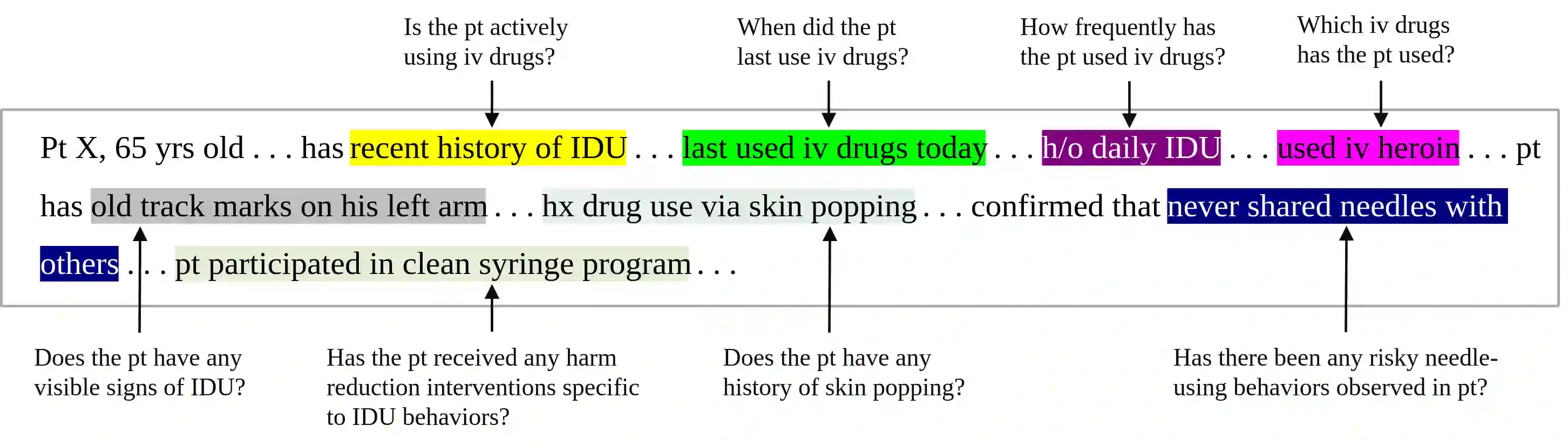
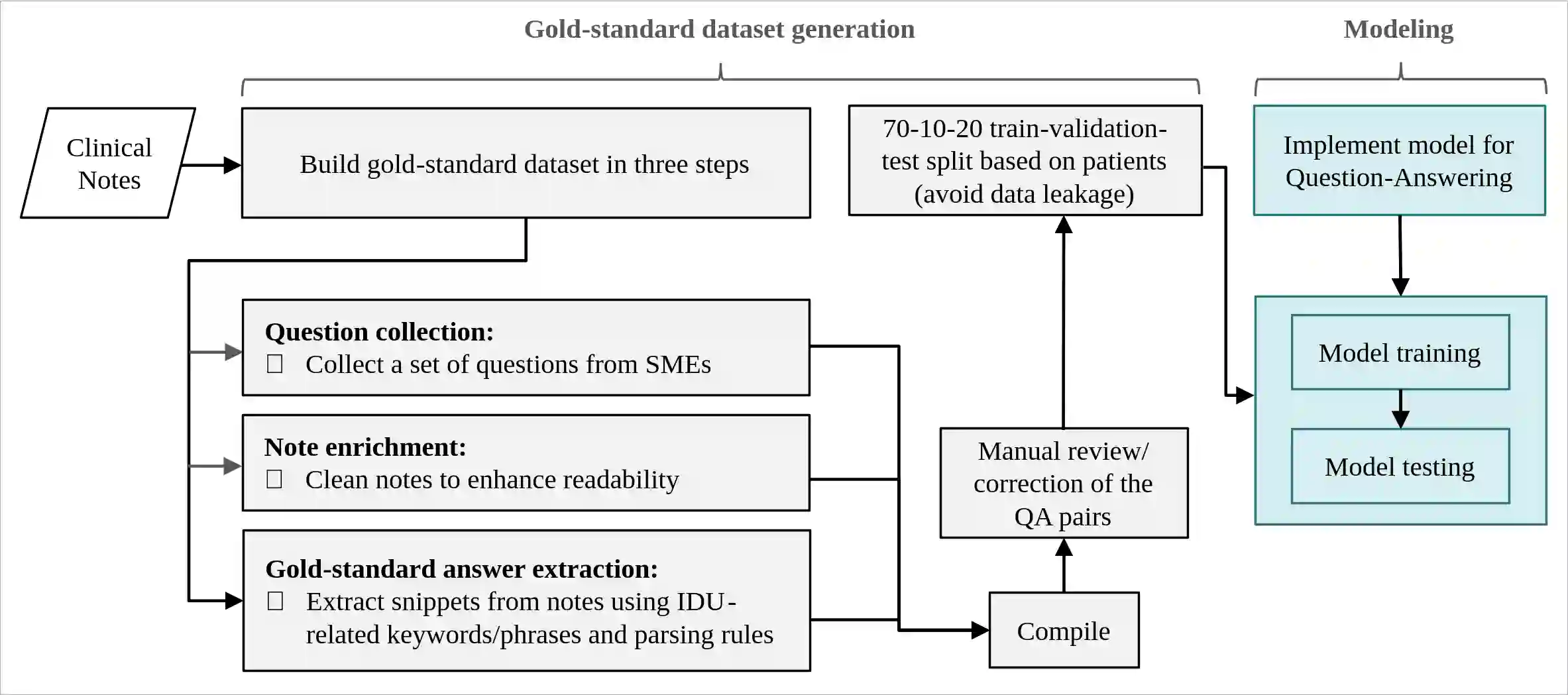
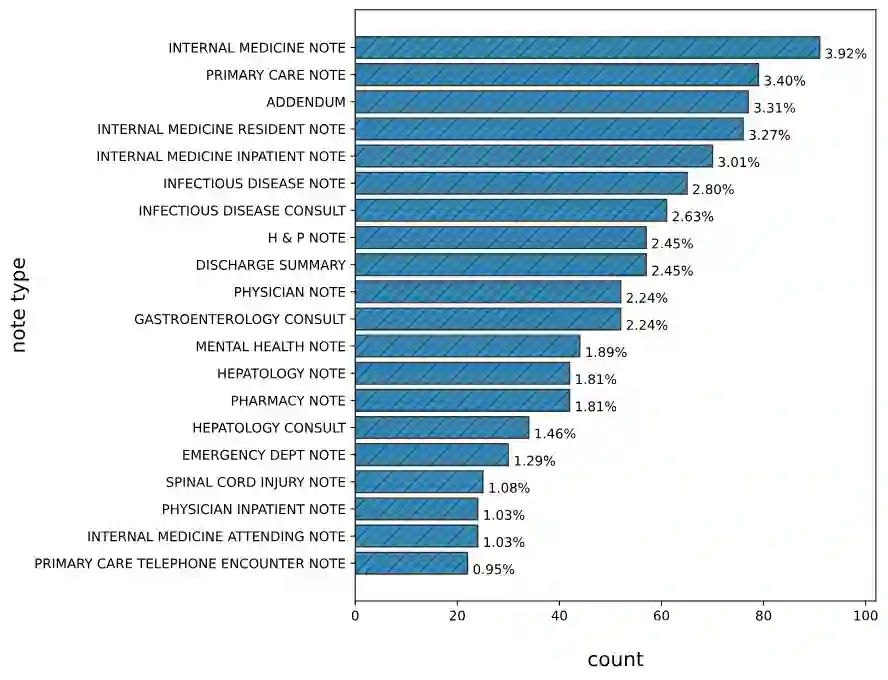
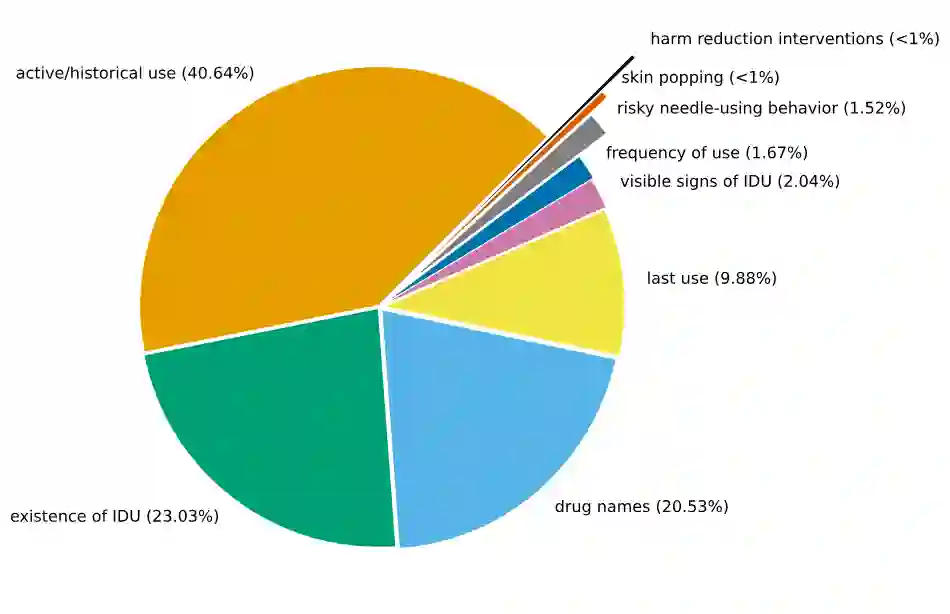
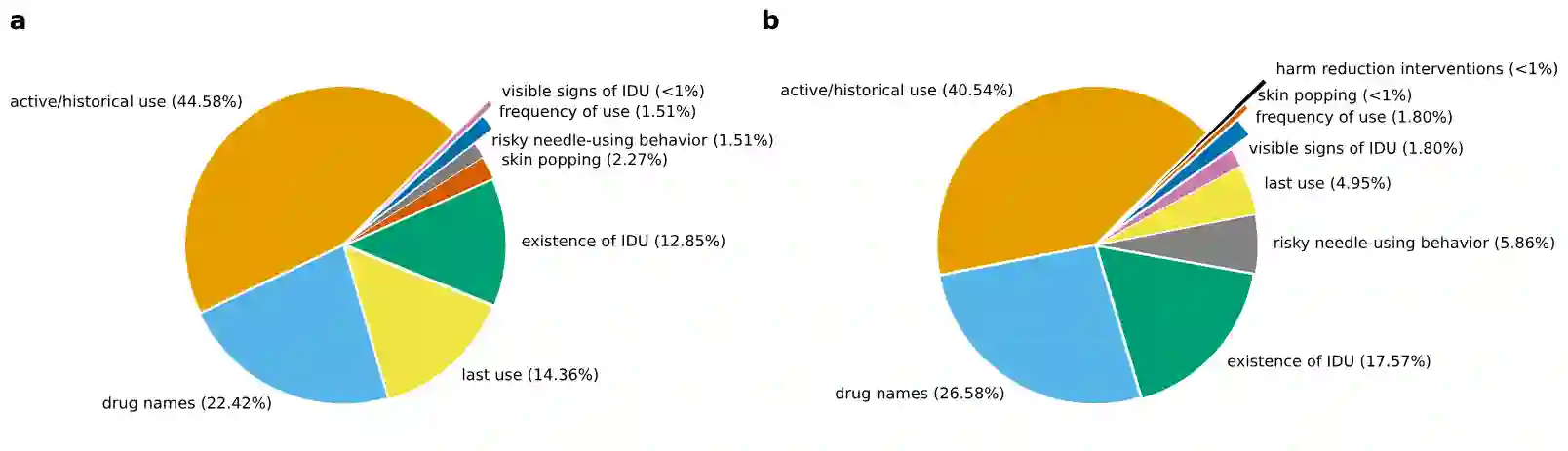
Background: Injection drug use (IDU) is a dangerous health behavior that increases mortality and morbidity. Identifying IDU early and initiating harm reduction interventions can benefit individuals at risk. However, extracting IDU behaviors from patients' electronic health records (EHR) is difficult because there is no International Classification of Disease (ICD) code and the only place IDU information can be indicated is unstructured free-text clinical notes. Although natural language processing can efficiently extract this information from unstructured data, there are no validated tools. Methods: To address this gap in clinical information, we design and demonstrate a question-answering (QA) framework to extract information on IDU from clinical notes. Our framework involves two main steps: (1) generating a gold-standard QA dataset and (2) developing and testing the QA model. We utilize 2323 clinical notes of 1145 patients sourced from the VA Corporate Data Warehouse to construct the gold-standard dataset for developing and evaluating the QA model. We also demonstrate the QA model's ability to extract IDU-related information on temporally out-of-distribution data. Results: Here we show that for a strict match between gold-standard and predicted answers, the QA model achieves 51.65% F1 score. For a relaxed match between the gold-standard and predicted answers, the QA model obtains 78.03% F1 score, along with 85.38% Precision and 79.02% Recall scores. Moreover, the QA model demonstrates consistent performance when subjected to temporally out-of-distribution data. Conclusions: Our study introduces a QA framework designed to extract IDU information from clinical notes, aiming to enhance the accurate and efficient detection of people who inject drugs, extract relevant information, and ultimately facilitate informed patient care.
翻译:暂无翻译