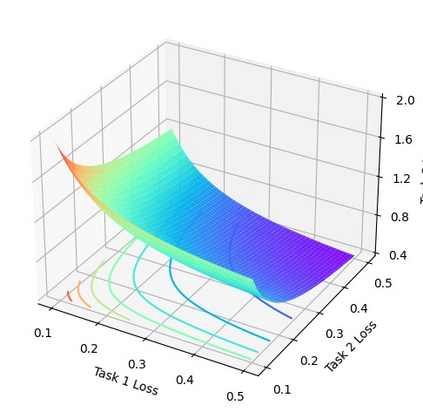
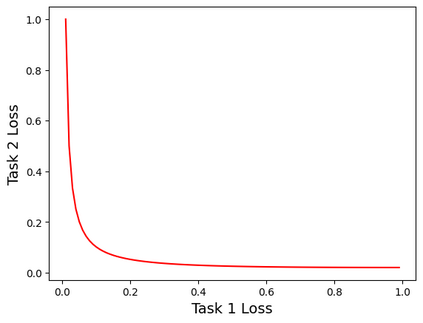
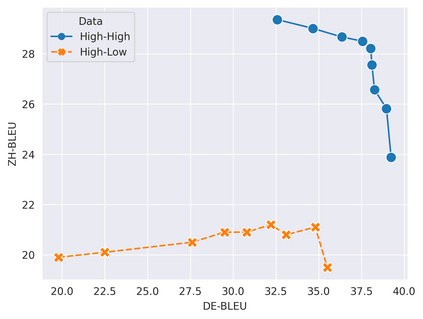
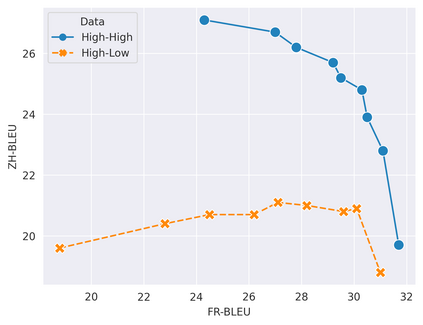
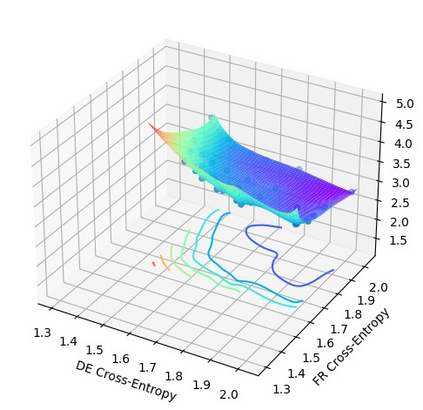
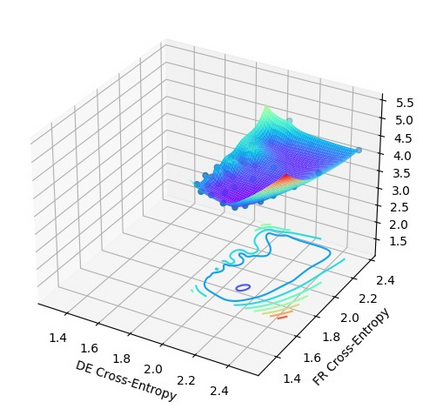
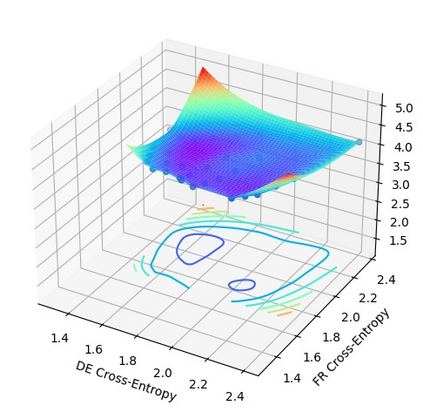
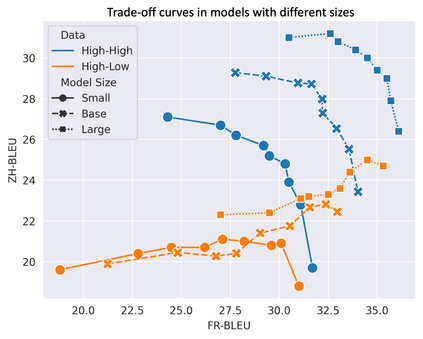
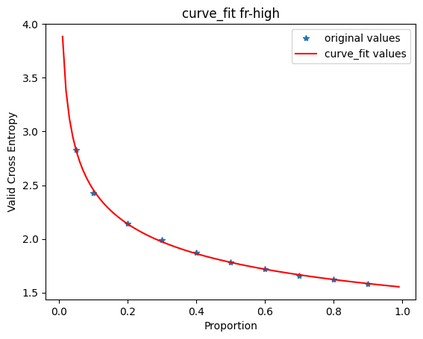
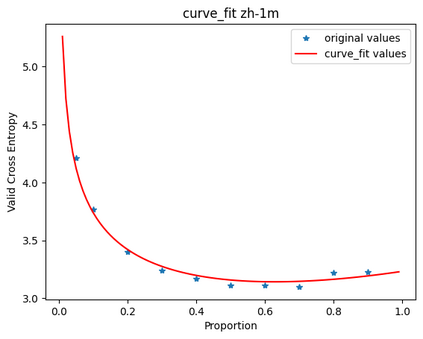
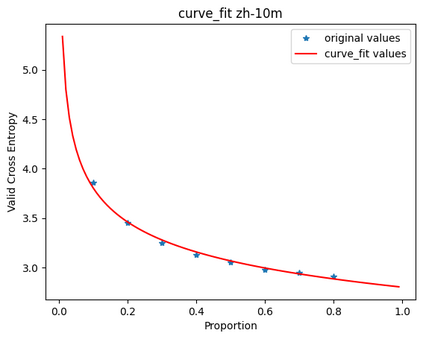
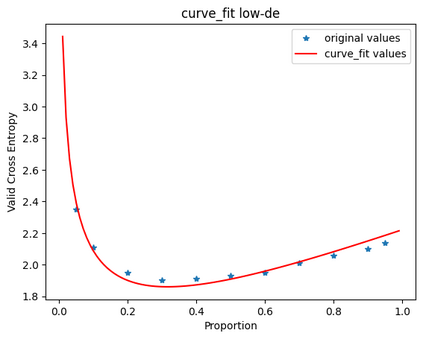
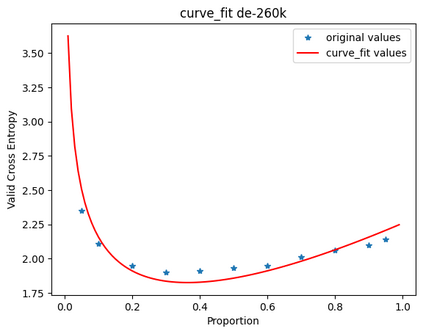
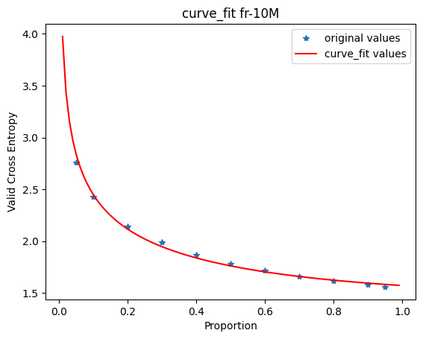
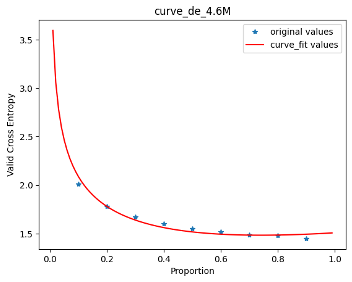
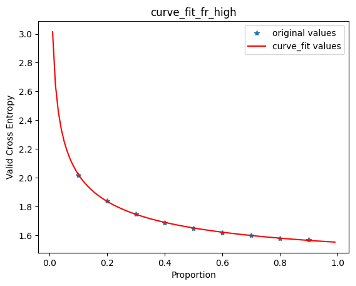
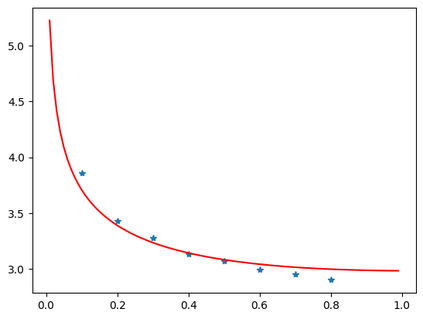
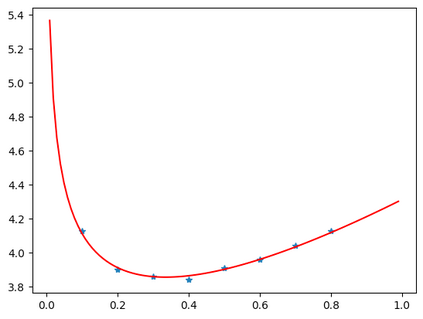
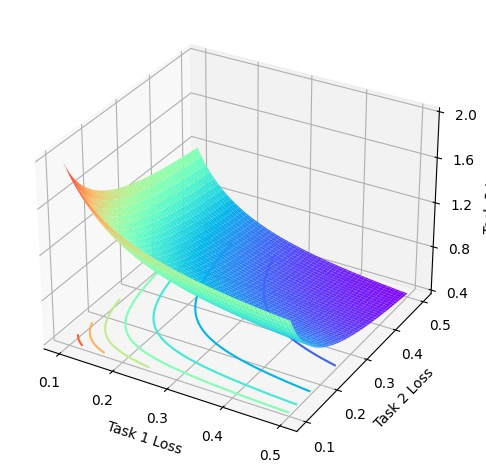
In this work, we study how the generalization performance of a given direction changes with its sampling ratio in Multilingual Neural Machine Translation (MNMT). By training over 200 multilingual models with various model sizes, directions, and total numbers of tasks, we find that scalarization leads to a multitask trade-off front that deviates from the traditional Pareto front when there exists data imbalance in the training corpus. That is, the performance of certain translation directions does not improve with the increase of its weight in the multi-task optimization objective, which poses greater challenge to improve the overall performance of all directions. Based on our observations, we propose the Double Power Law to predict the unique performance trade-off front in MNMT, which is robust across various languages, data adequacy and number of tasks. Finally, we formulate sample ratio selection in MNMT as an optimization problem based on the Double Power Law, which achieves better performance than temperature searching and gradient manipulation methods using up to half of the total training budget in our experiments.
翻译:在这项工作中,我们研究了给定方向的广义性能如何随其采样比例在多语言神经机器翻译(MNMT)中改变。通过训练超过200个具有各种模型大小,方向和任务总数的多语言模型,我们发现当训练语料库中存在数据不平衡时,标量化会导致多任务折衷前沿偏离传统的帕累托前沿。也就是说,对于某些翻译方向的性能不随其在多任务优化目标中的权重增加而提高,这对于提高所有方向的整体性能提出了更大的挑战。基于我们的观察,我们提出了双幂律以预测MNMT中的独特性能折衷前沿,该前沿在各种语言,数据充足性和任务数量方面都具有鲁棒性。最后,我们将MNMT中的采样比例选择建模为基于双幂律的优化问题,在我们的实验中使用的训练预算的一半以内,其性能优于温度搜索和梯度操作方法。