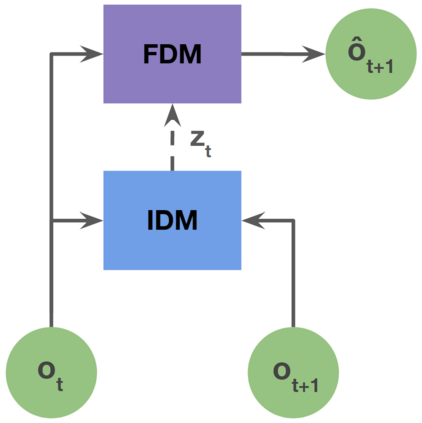
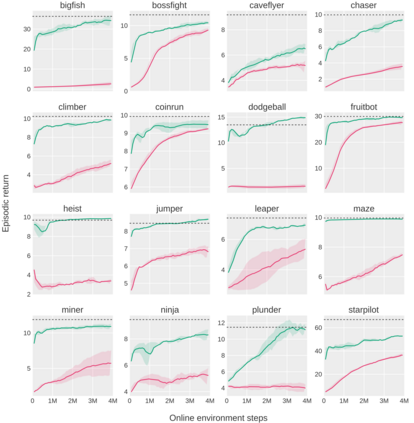
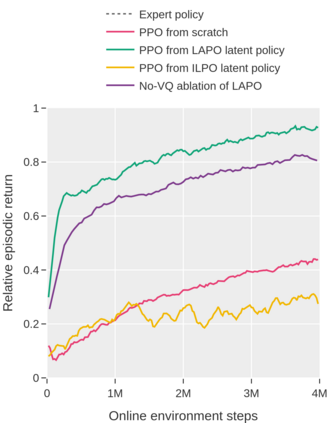
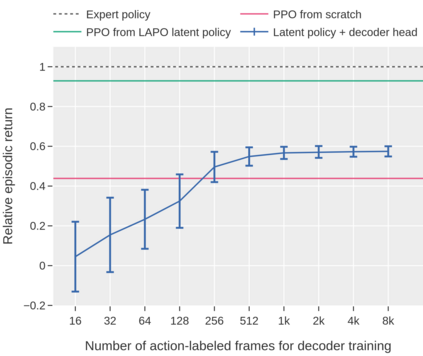
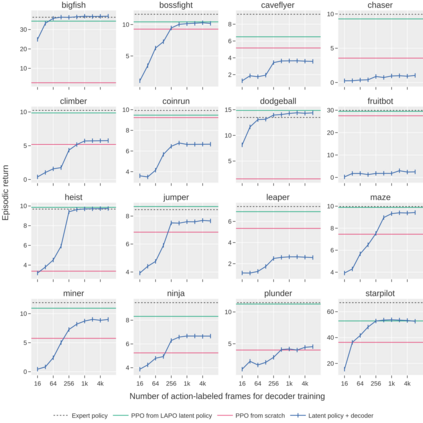
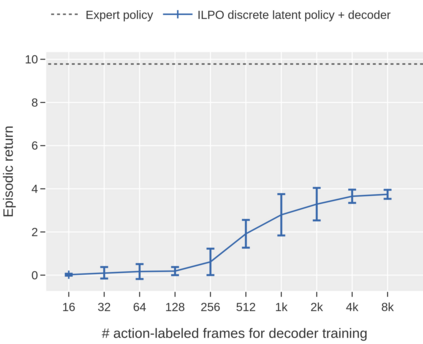
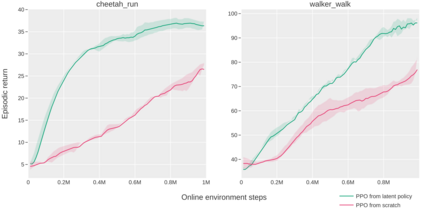
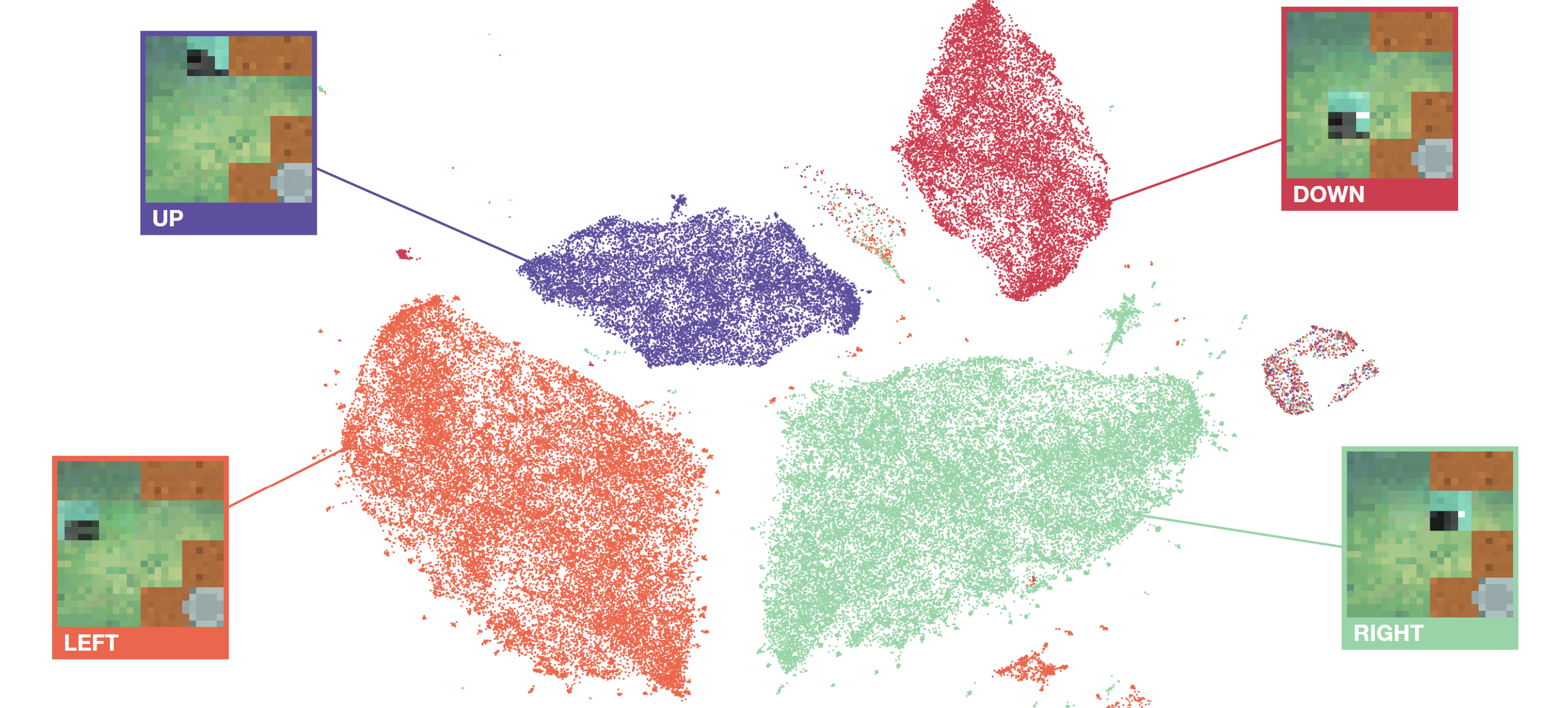
Pre-training large models on vast amounts of web data has proven to be an effective approach for obtaining powerful, general models in several domains, including language and vision. However, this paradigm has not yet taken hold in deep reinforcement learning (RL). This gap is due to the fact that the most abundant form of embodied behavioral data on the web consists of videos, which do not include the action labels required by existing methods for training policies from offline data. We introduce Latent Action Policies from Observation (LAPO), a method to infer latent actions and, consequently, latent-action policies purely from action-free demonstrations. Our experiments on challenging procedurally-generated environments show that LAPO can act as an effective pre-training method to obtain RL policies that can then be rapidly fine-tuned to expert-level performance. Our approach serves as a key stepping stone to enabling the pre-training of powerful, generalist RL models on the vast amounts of action-free demonstrations readily available on the web.
翻译:暂无翻译