
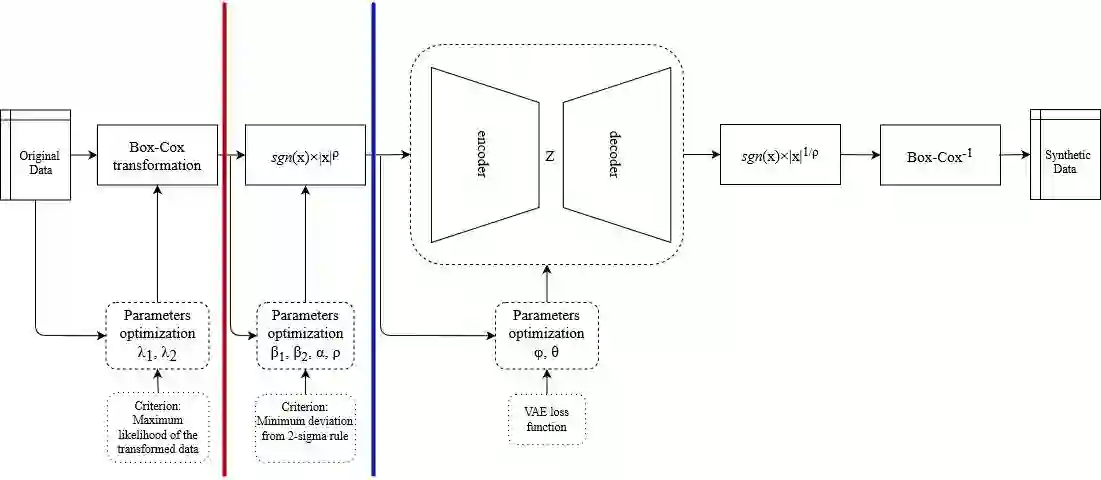
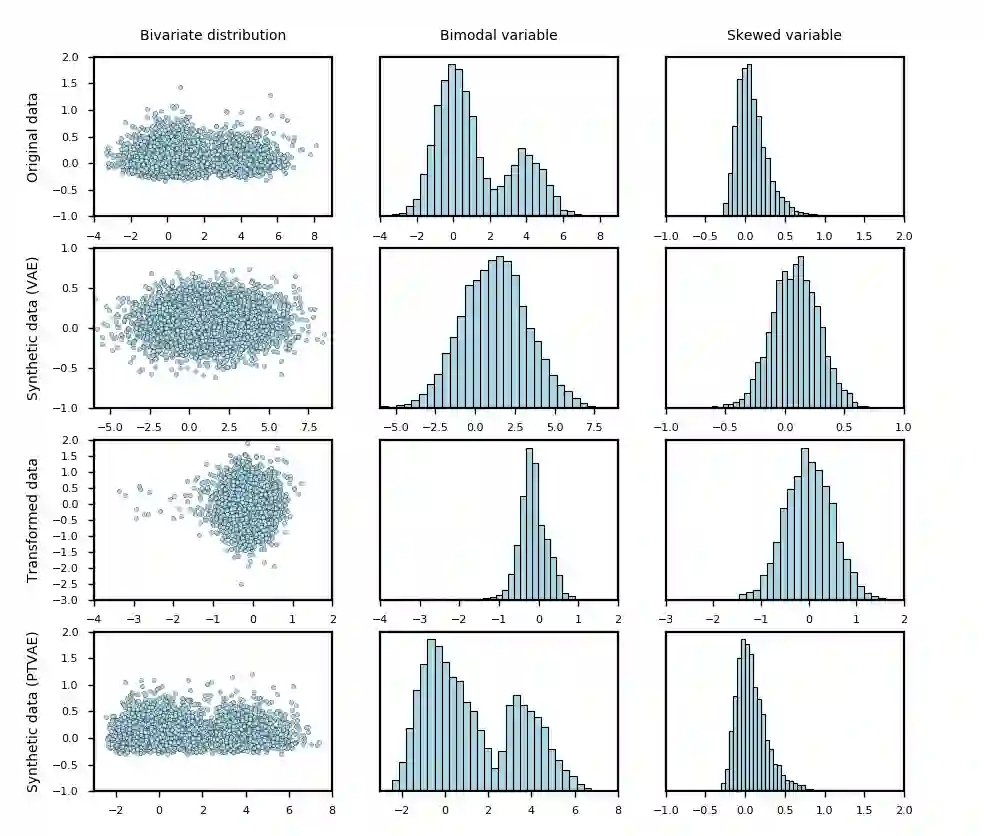
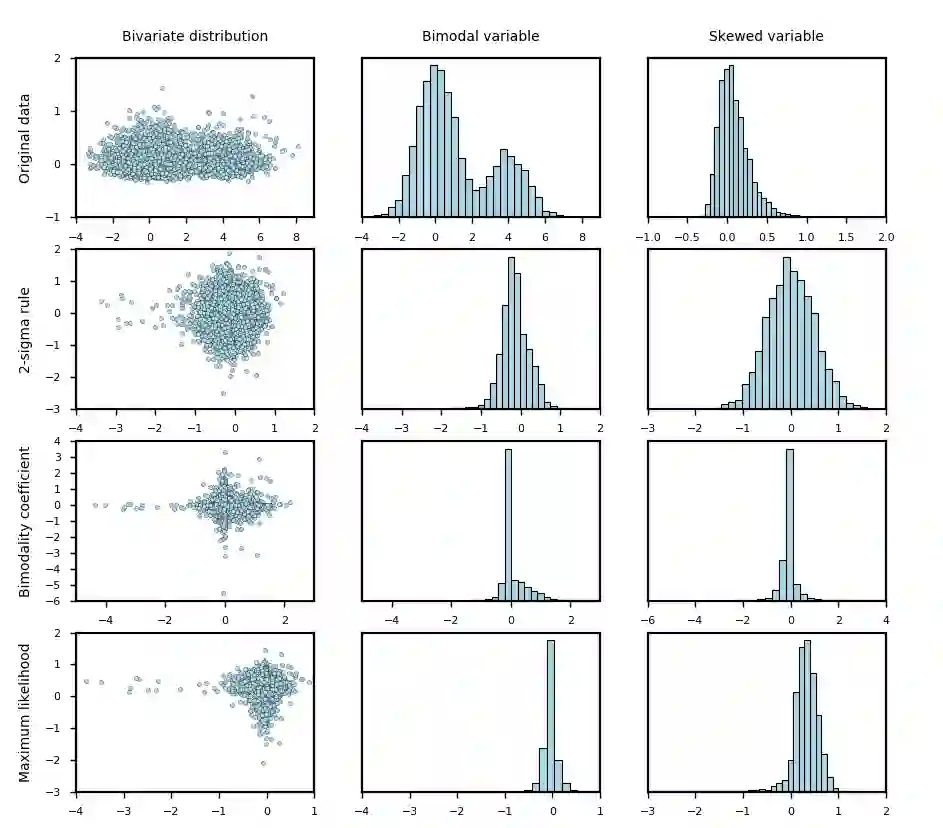
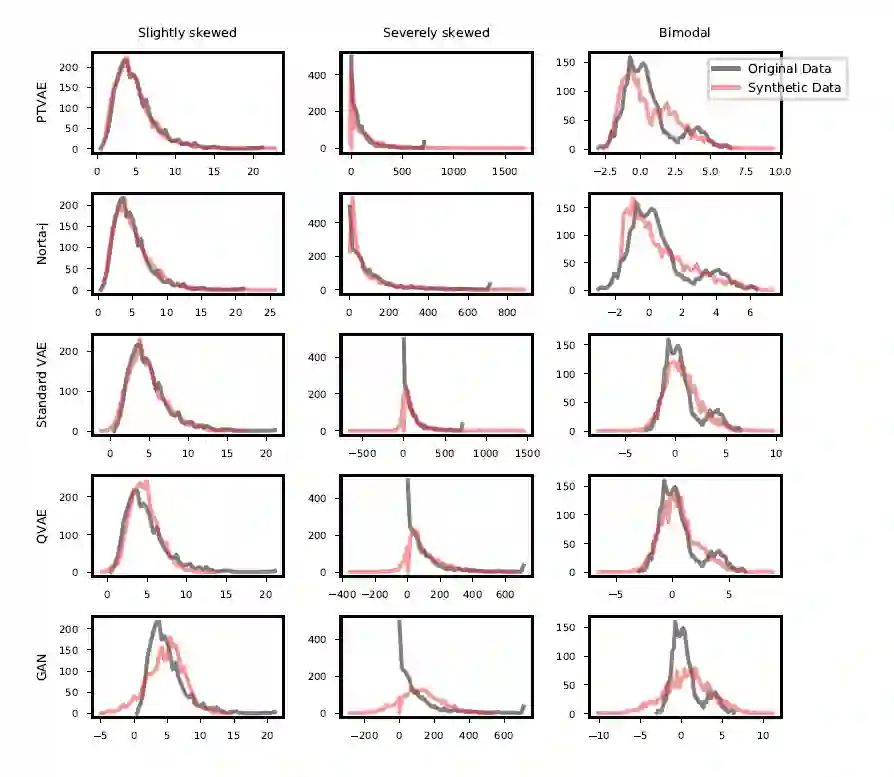
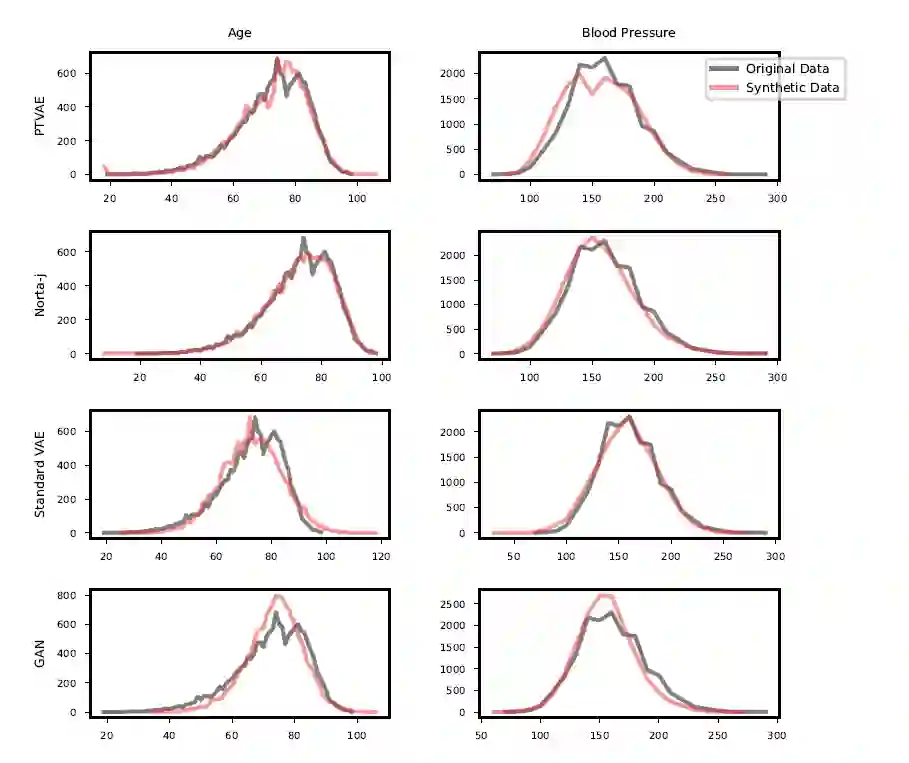
Synthetic data generation is of great interest in diverse applications, such as for privacy protection. Deep generative models, such as variational autoencoders (VAEs), are a popular approach for creating such synthetic datasets from original data. Despite the success of VAEs, there are limitations when it comes to the bimodal and skewed marginal distributions. These deviate from the unimodal symmetric distributions that are encouraged by the normality assumption typically used for the latent representations in VAEs. While there are extensions that assume other distributions for the latent space, this does not generally increase flexibility for data with many different distributions. Therefore, we propose a novel method, pre-transformation variational autoencoders (PTVAEs), to specifically address bimodal and skewed data, by employing pre-transformations at the level of original variables. Two types of transformations are used to bring the data close to a normal distribution by a separate parameter optimization for each variable in a dataset. We compare the performance of our method with other state-of-the-art methods for synthetic data generation. In addition to the visual comparison, we use a utility measurement for a quantitative evaluation. The results show that the PTVAE approach can outperform others in both bimodal and skewed data generation. Furthermore, the simplicity of the approach makes it usable in combination with other extensions of VAE.
翻译:合成数据生成对于多种应用,例如隐私保护,具有极大的兴趣。深基因模型,例如变异自动编码器(VAEs),是利用原始数据创建此类合成数据集的流行方法。尽管VAEs取得了成功,但是在双式和偏斜边缘分布方面存在着局限性。它们不同于通常用于VAEs潜在代表的正常假设所鼓励的单式对称分布。虽然有一些扩展,假定了潜在空间的其他分布,但通常不会增加数据在许多不同分布中的灵活性。因此,我们提出了一个创新方法,即变异前变异自动编码器(PTVAEs),具体处理双式和偏斜式数据,在原始变量一级采用预变形和偏斜式数据分布。使用两种变异类型使数据接近于正常分布,在数据集中对每种变量进行单独的参数优化。我们用我们的方法的性能与其他状态-艺术方法在合成数据生成方面的弹性方法相比,我们提出了一种新颖的方法,在图像-变异性数据生成中,我们用另一种变异的定量方法来显示另一个变异性方法。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


