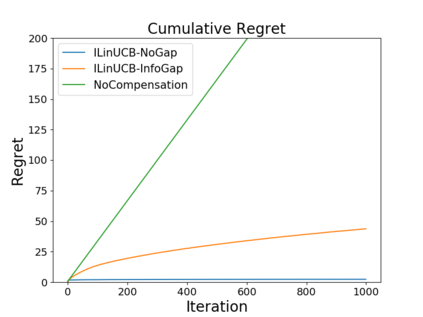
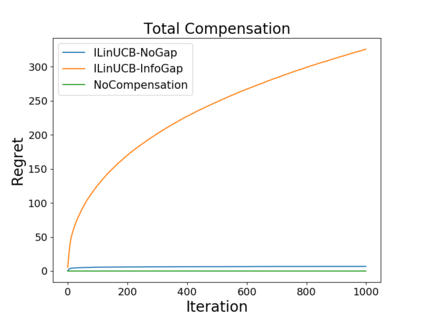
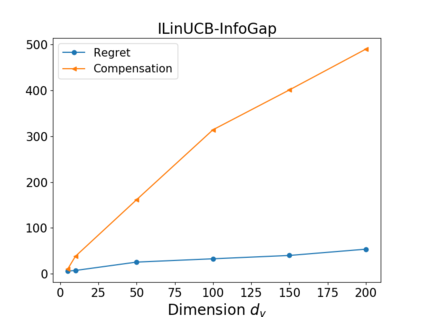
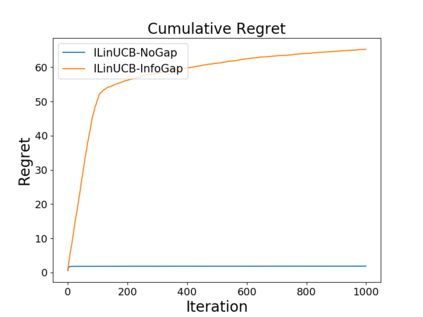
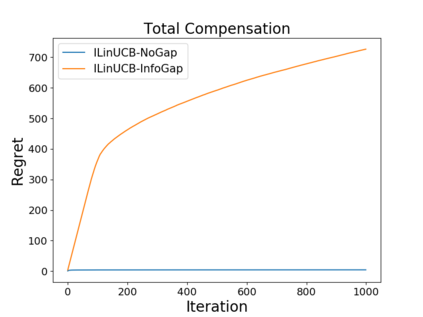
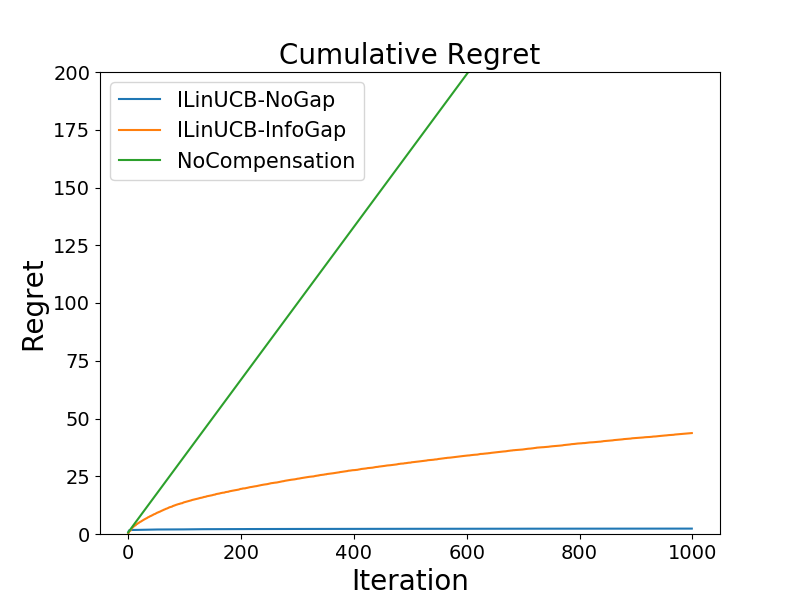
We study the problem of incentivizing exploration for myopic users in linear bandits, where the users tend to exploit arm with the highest predicted reward instead of exploring. In order to maximize the long-term reward, the system offers compensation to incentivize the users to pull the exploratory arms, with the goal of balancing the trade-off among exploitation, exploration and compensation. We consider a new and practically motivated setting where the context features observed by the user are more informative than those used by the system, e.g., features based on users' private information are not accessible by the system. We propose a new method to incentivize exploration under such information gap, and prove that the method achieves both sublinear regret and sublinear compensation. We theoretical and empirically analyze the added compensation due to the information gap, compared with the case that the system has access to the same context features as the user, i.e., without information gap. We also provide a compensation lower bound of our problem.
翻译:我们研究在线性强盗中鼓励对近视使用者进行探索的问题,用户往往以预测最高的报酬而不是探索探索利用手臂。为了最大限度地获得长期奖励,该系统提供补偿,激励使用者拔出探索性武器,目的是平衡开发、勘探和补偿之间的取舍。我们考虑一种新的、实际的、有动机的环境,用户观察到的背景特征比系统使用的背景特征更加丰富,例如,系统无法获取基于用户私人信息的特征。我们提出了鼓励在这种信息差距下进行探索的新方法,并证明该方法既实现了亚线性遗憾,又实现了亚线性赔偿。我们从理论上和实验上分析了由于信息差距而增加的补偿,相比之下,系统可以使用与用户相同的背景特征,即没有信息差距。我们还提供了我们问题较少的补偿。