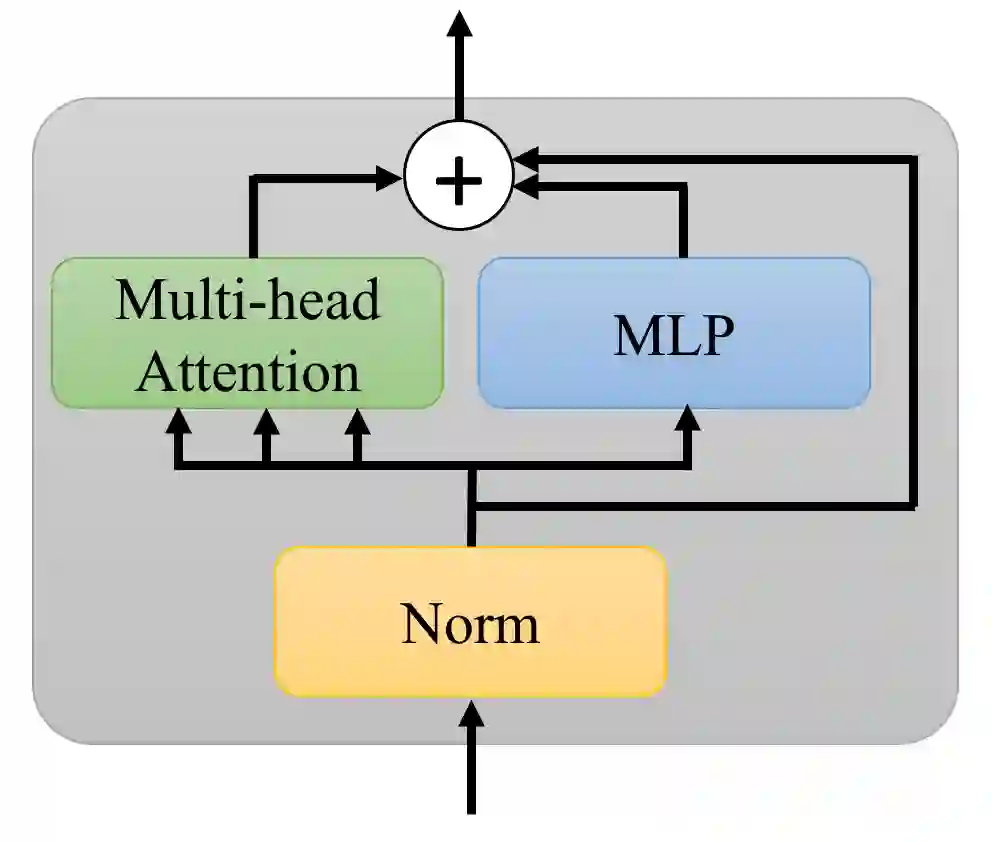
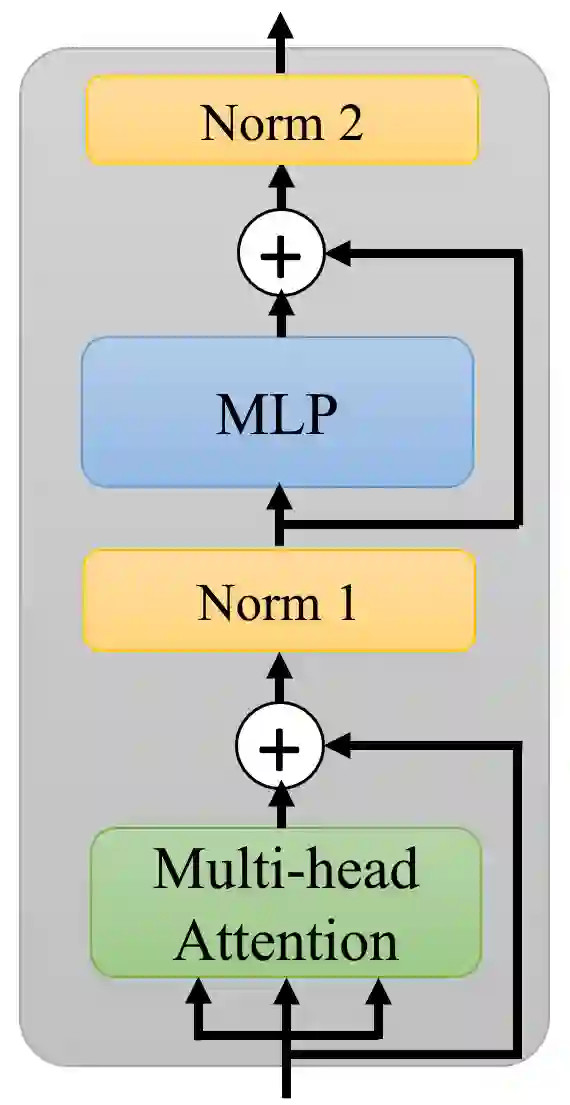
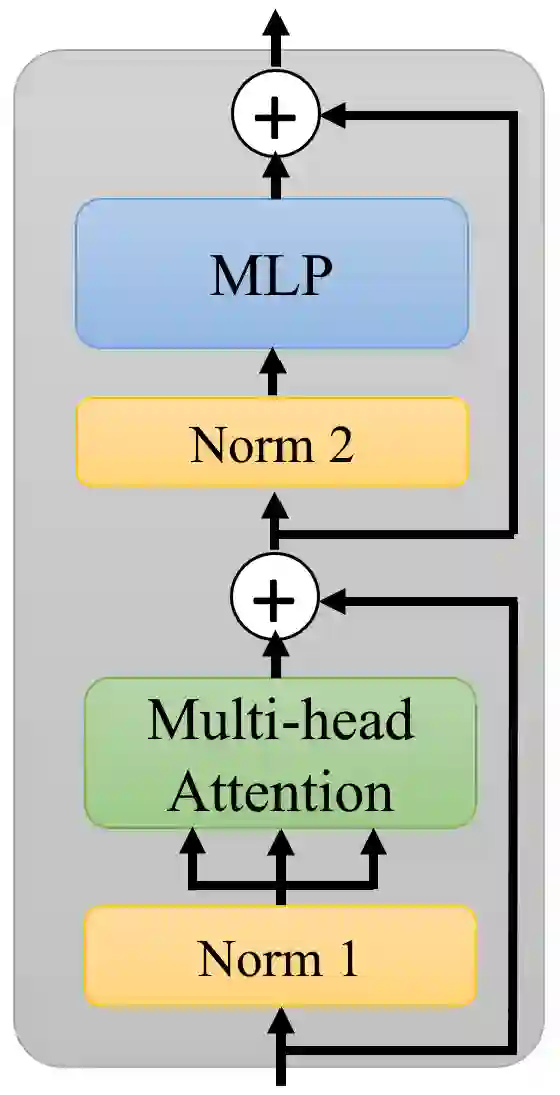
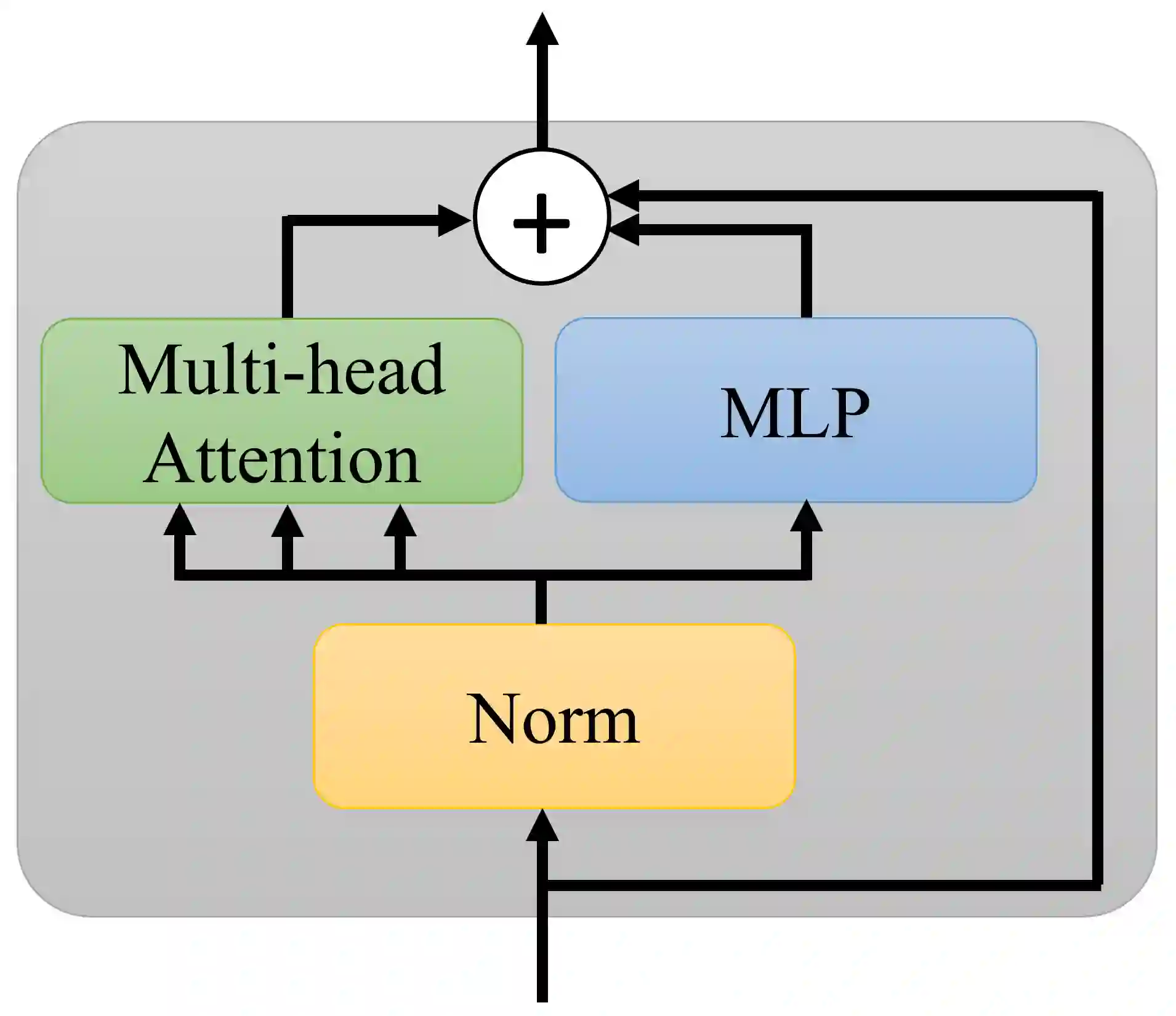
Transformer layers, which use an alternating pattern of multi-head attention and multi-layer perceptron (MLP) layers, provide an effective tool for a variety of machine learning problems. As the transformer layers use residual connections to avoid the problem of vanishing gradients, they can be viewed as the numerical integration of a differential equation. In this extended abstract, we build upon this connection and propose a modification of the internal architecture of a transformer layer. The proposed model places the multi-head attention sublayer and the MLP sublayer parallel to each other. Our experiments show that this simple modification improves the performance of transformer networks in multiple tasks. Moreover, for the image classification task, we show that using neural ODE solvers with a sophisticated integration scheme further improves performance.
翻译:变压器层使用多头注意和多层光谱层的交替模式,为各种机器学习问题提供了一个有效的工具。变压器层使用残余连接以避免渐变梯度的消失问题,它们可以被视为差异方程的数值整合。在这个扩展的抽象中,我们利用这一连接,并提议修改变压层的内部结构。拟议的模型将多头注意子层和多层光谱层平行。我们的实验显示,这种简单修改可以改善变压器网络在多重任务中的性能。此外,对于图像分类任务,我们显示,使用有复杂集成计划的神经解析器可以进一步提高性能。