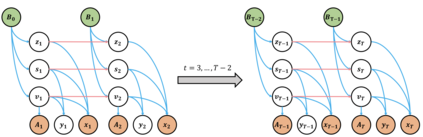
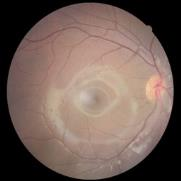
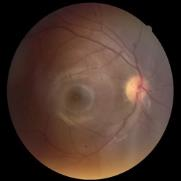
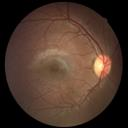
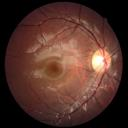
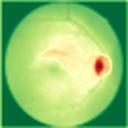
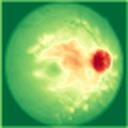
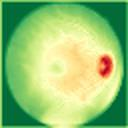
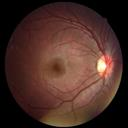
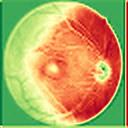
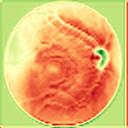
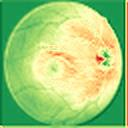
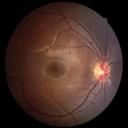
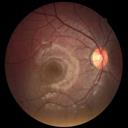
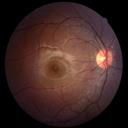
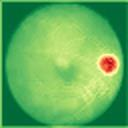
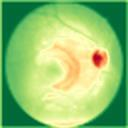
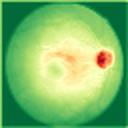
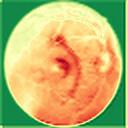
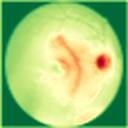
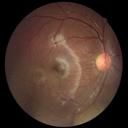
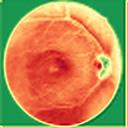
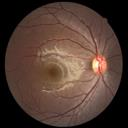
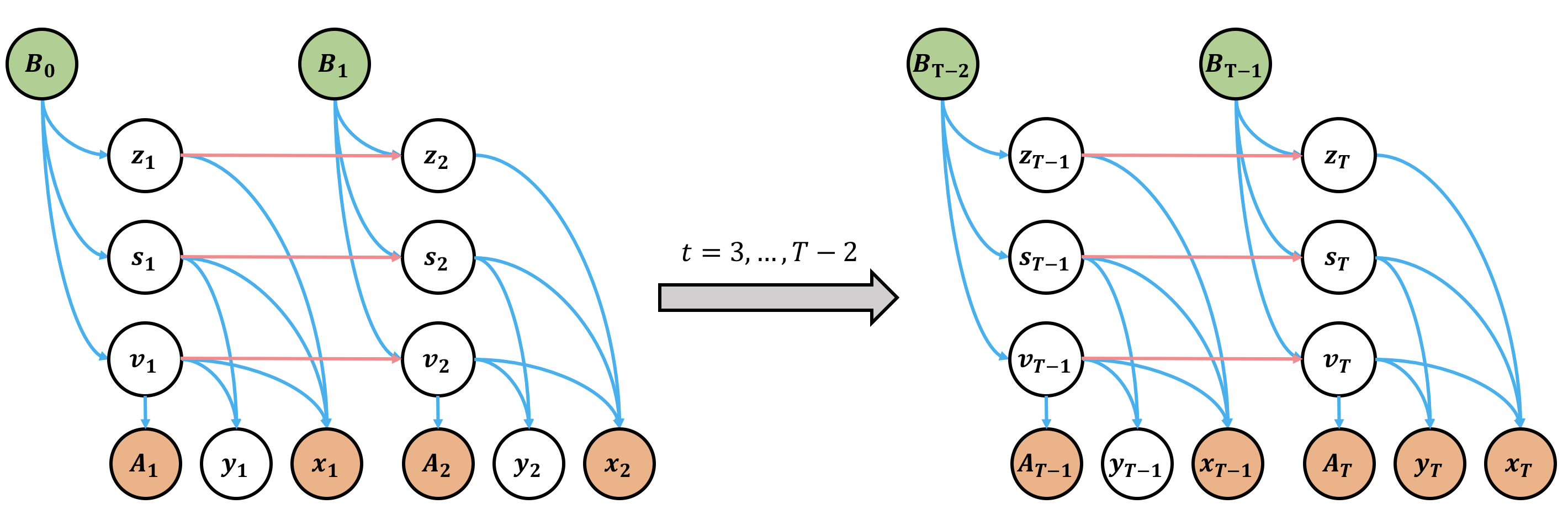
We propose a causal hidden Markov model to achieve robust prediction of irreversible disease at an early stage, which is safety-critical and vital for medical treatment in early stages. Specifically, we introduce the hidden variables which propagate to generate medical data at each time step. To avoid learning spurious correlation (e.g., confounding bias), we explicitly separate these hidden variables into three parts: a) the disease (clinical)-related part; b) the disease (non-clinical)-related part; c) others, with only a),b) causally related to the disease however c) may contain spurious correlations (with the disease) inherited from the data provided. With personal attributes and the disease label respectively provided as side information and supervision, we prove that these disease-related hidden variables can be disentangled from others, implying the avoidance of spurious correlation for generalization to medical data from other (out-of-) distributions. Guaranteed by this result, we propose a sequential variational auto-encoder with a reformulated objective function. We apply our model to the early prediction of peripapillary atrophy and achieve promising results on out-of-distribution test data. Further, the ablation study empirically shows the effectiveness of each component in our method. And the visualization shows the accurate identification of lesion regions from others.
翻译:我们提出一个因果隐蔽的马尔科夫模型,以便在早期阶段对不可逆转的疾病作出稳健的预测,这种模型对安全至关重要,对早期治疗至关重要。具体地说,我们引入了传播的隐藏变量,以在每一个阶段生成医疗数据。为了避免学习虚假的相关性(例如混淆偏见),我们将这些隐藏变量明确分为三个部分:(a) 疾病(临床)相关部分;(b) 疾病(非临床)相关部分;(c) 与疾病有因果关系的其他部分(只有a)、(b) 但与疾病有因果关系的(c) 可能包含从所提供的数据中继承下来的(与疾病)虚假的相互关系。用个人属性和疾病标签分别作为侧边际信息和监督提供的,我们证明这些与疾病有关的隐藏变量可能与其他变量脱钩,意味着避免将其他(临床)传播的医学数据与一般化的虚假关联;(b) 通过这一结果,我们建议采用一个顺序变异自动编码,并重新设定客观功能。我们用我们的模型来早期预测所提供的数据的(与疾病有关),分别作为侧边际信息和监督。我们证明这些与疾病相关的个人属性和疾病标签标签的标签标签,我们每个图像分析结果显示我们每个前景分析结果。