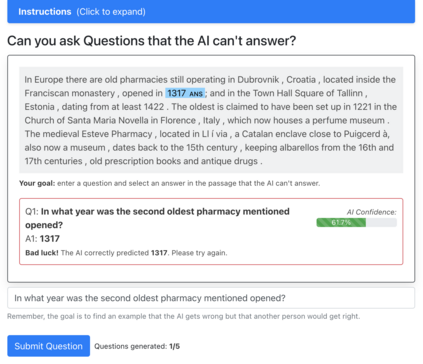
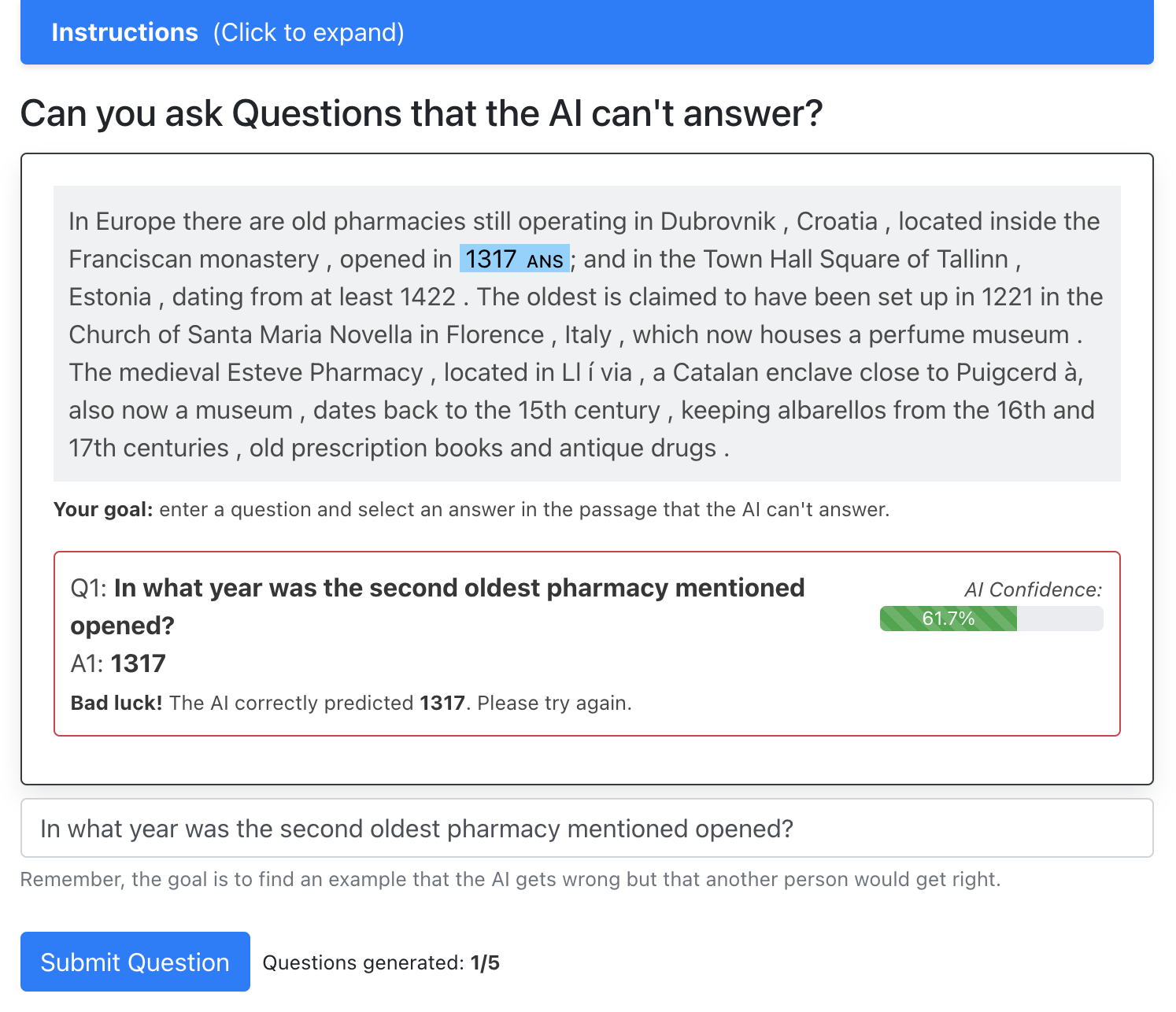
Despite recent progress, state-of-the-art question answering models remain vulnerable to a variety of adversarial attacks. While dynamic adversarial data collection, in which a human annotator tries to write examples that fool a model-in-the-loop, can improve model robustness, this process is expensive which limits the scale of the collected data. In this work, we are the first to use synthetic adversarial data generation to make question answering models more robust to human adversaries. We develop a data generation pipeline that selects source passages, identifies candidate answers, generates questions, then finally filters or re-labels them to improve quality. Using this approach, we amplify a smaller human-written adversarial dataset to a much larger set of synthetic question-answer pairs. By incorporating our synthetic data, we improve the state-of-the-art on the AdversarialQA dataset by 3.7F1 and improve model generalisation on nine of the twelve MRQA datasets. We further conduct a novel human-in-the-loop evaluation to show that our models are considerably more robust to new human-written adversarial examples: crowdworkers can fool our model only 8.8% of the time on average, compared to 17.6% for a model trained without synthetic data.
翻译:尽管最近取得了进展,最先进的回答问题模型仍然容易受到各种对抗性攻击的伤害。动态对抗性数据采集工具试图写出一些例子,在其中,一个人类旁观者试图写出那些愚弄模型的模型能够提高模型的稳健性,但这个过程费用昂贵,限制了所收集数据的规模。在这项工作中,我们首先使用合成对抗性数据生成方法,使回答模型的模型对人类对手更加有力。我们开发了一个数据生成管道,选择源通道,确定候选答案,提出问题,然后最后过滤或重新标出它们来提高质量。我们采用这种方法,将一个较小的人写对抗性数据套扩大为一组更大的合成问答配对。通过整合我们的合成数据,我们改进了Adversarial QA数据集中由3.7F1组成的最新版,改进了12个MSQA数据集中9个数据集的模型的典型化。我们进一步进行了新的“人对窗口”评估,以显示我们的模型对于新的人写敌对性模型来说,比新的模型要强得多。我们用17个模型的模型比较了8 %的平均数据。