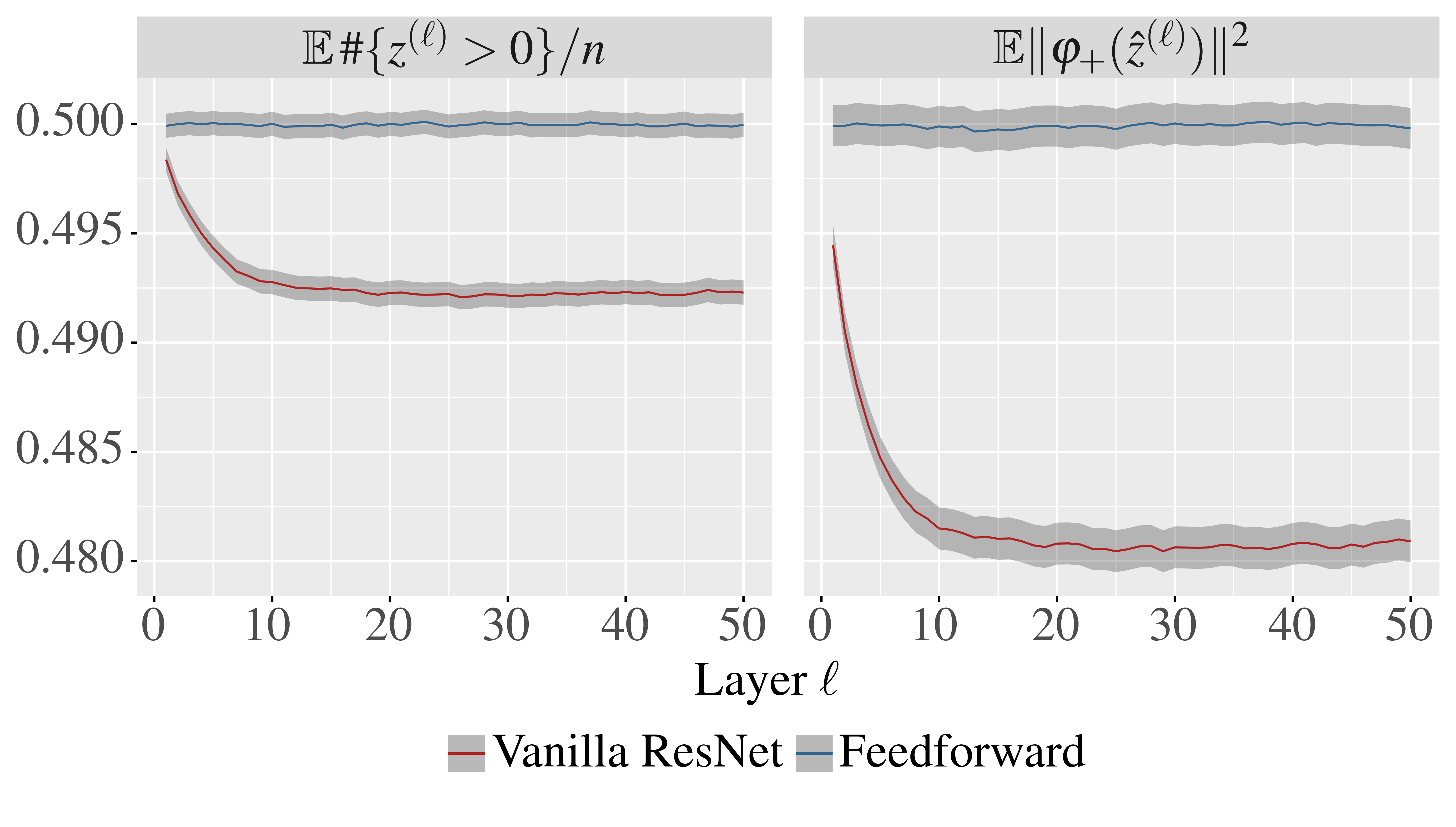
Theoretical results show that neural networks can be approximated by Gaussian processes in the infinite-width limit. However, for fully connected networks, it has been previously shown that for any fixed network width, $n$, the Gaussian approximation gets worse as the network depth, $d$, increases. Given that modern networks are deep, this raises the question of how well modern architectures, like ResNets, are captured by the infinite-width limit. To provide a better approximation, we study ReLU ResNets in the infinite-depth-and-width limit, where both depth and width tend to infinity as their ratio, $d/n$, remains constant. In contrast to the Gaussian infinite-width limit, we show theoretically that the network exhibits log-Gaussian behaviour at initialization in the infinite-depth-and-width limit, with parameters depending on the ratio $d/n$. Using Monte Carlo simulations, we demonstrate that even basic properties of standard ResNet architectures are poorly captured by the Gaussian limit, but remarkably well captured by our log-Gaussian limit. Moreover, our analysis reveals that ReLU ResNets at initialization are hypoactivated: fewer than half of the ReLUs are activated. Additionally, we calculate the interlayer correlations, which have the effect of exponentially increasing the variance of the network output. Based on our analysis, we introduce Balanced ResNets, a simple architecture modification, which eliminates hypoactivation and interlayer correlations and is more amenable to theoretical analysis.
翻译:理论结果显示, 神经网络可以通过高斯进程在无限宽度限制下近似于神经网络。 但是, 对于完全连接的网络来说, 此前已经显示, 对任何固定网络宽度而言, 美元, 美元, 高斯近似值随着网络深度的提高而恶化。 鉴于现代网络是深度的, 这就提出了如何用无限宽限来捕捉像ResNets这样的现代架构。 为了提供更好的近似度, 我们研究了在无限深度和宽度限制下ReLU ResNets, 其深度和宽度都倾向于不精确, 其比重( $d/ n$ ) 。 与高斯网络的无限宽度限制相比, 我们理论上显示, 网络在无限深度和宽度限制的初始化时, 包括参数, $d/ n$。 我们利用蒙特卡洛的模拟, 我们证明标准 ResNet 架构的基本特性, 其深度和宽度往往被高点测为精确度, 而在我们开始的直径的直径网络内部分析中,, 也明显地展示了我们的正值 。