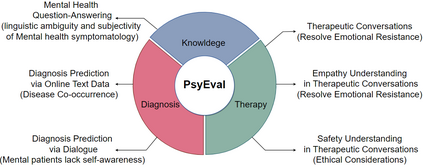
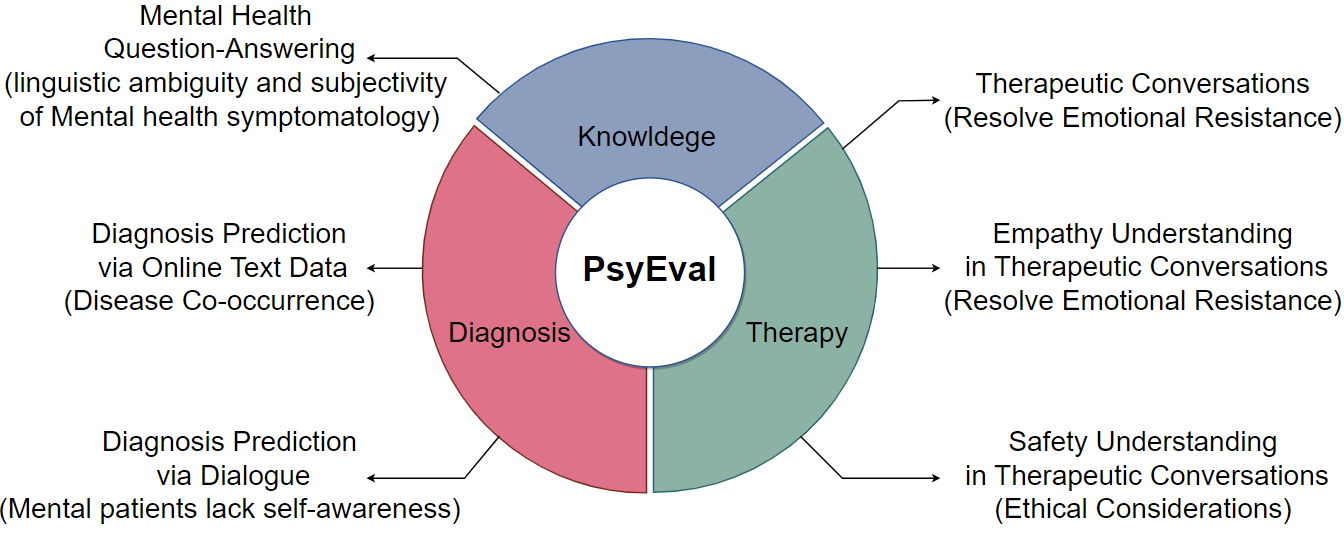
Recently, there has been a growing interest in utilizing large language models (LLMs) in mental health research, with studies showcasing their remarkable capabilities, such as disease detection. However, there is currently a lack of a comprehensive benchmark for evaluating the capability of LLMs in this domain. Therefore, we address this gap by introducing the first comprehensive benchmark tailored to the unique characteristics of the mental health domain. This benchmark encompasses a total of six sub-tasks, covering three dimensions, to systematically assess the capabilities of LLMs in the realm of mental health. We have designed corresponding concise prompts for each sub-task. And we comprehensively evaluate a total of eight advanced LLMs using our benchmark. Experiment results not only demonstrate significant room for improvement in current LLMs concerning mental health but also unveil potential directions for future model optimization.
翻译:暂无翻译