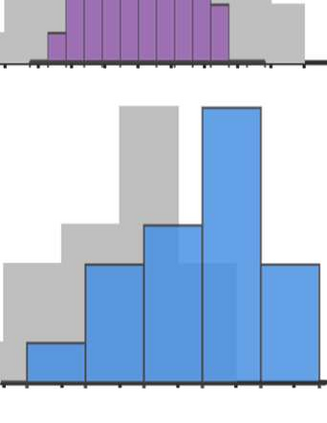
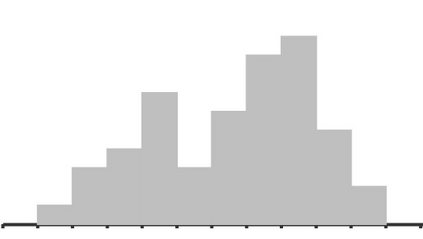
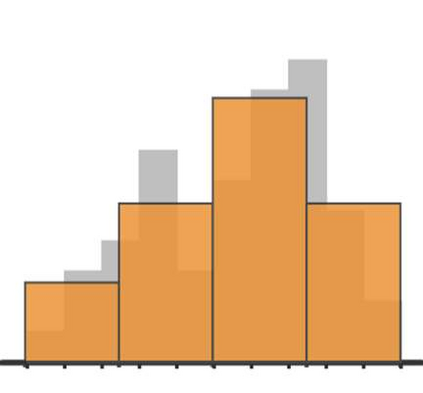
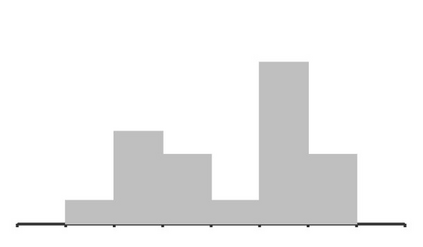
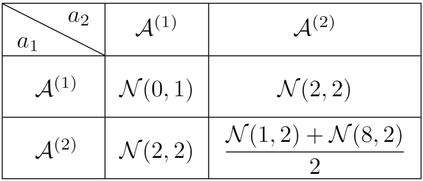
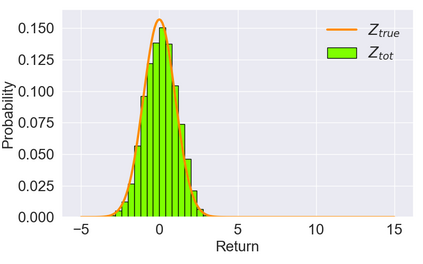
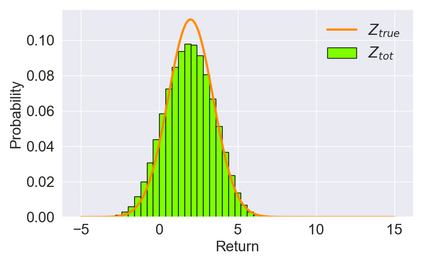
In cooperative multi-agent tasks, a team of agents jointly interact with an environment by taking actions, receiving a team reward and observing the next state. During the interactions, the uncertainty of environment and reward will inevitably induce stochasticity in the long-term returns and the randomness can be exacerbated with the increasing number of agents. However, most of the existing value-based multi-agent reinforcement learning (MARL) methods only model the expectations of individual Q-values and global Q-value, ignoring such randomness. Compared to the expectations of the long-term returns, it is more preferable to directly model the stochasticity by estimating the returns through distributions. With this motivation, this work proposes DQMIX, a novel value-based MARL method, from a distributional perspective. Specifically, we model each individual Q-value with a categorical distribution. To integrate these individual Q-value distributions into the global Q-value distribution, we design a distribution mixing network, based on five basic operations on the distribution. We further prove that DQMIX satisfies the \emph{Distributional-Individual-Global-Max} (DIGM) principle with respect to the expectation of distribution, which guarantees the consistency between joint and individual greedy action selections in the global Q-value and individual Q-values. To validate DQMIX, we demonstrate its ability to factorize a matrix game with stochastic rewards. Furthermore, the experimental results on a challenging set of StarCraft II micromanagement tasks show that DQMIX consistently outperforms the value-based multi-agent reinforcement learning baselines.
翻译:在合作性多试剂任务中,一个代理人团队通过采取行动、获得团队奖赏和观察下一个状态与环境共同互动。在互动中,环境和奖励的不确定性将不可避免地导致长期回报的随机性,而随着代理数量的增加,随机性将加剧。然而,大多数现有的基于价值的多试剂强化学习(MARL)方法仅模拟个人Q值和全球Q值的预期值,忽略这种随机性。与长期回报的预期相比,通过分布估计回报直接模拟随机性更为可取。有了这种动力,这项工作将提出基于长期回报的不确定性和奖赏性,从分布角度,一个新的基于价值的MARL方法。具体地说,我们以绝对分布方式模拟个人Q值分配的预期值,将个人Q值分配的预期值纳入全球质量分布中,我们设计了一个基于基于五种基础分布操作的分布混合网络。我们进一步证明,DQIX满足了通过分配方式估算回报率的模型。QQQDMIX, QDQDMIX, 一个新的基于价值的基于新数值的数值的数值方法方法方法, 展示了全球内部价值的数值的数值, 和数值的数值的数值的数值的数值的数值,显示了全球的数值的数值的数值的数值的数值的数值的数值,显示了全球的数值的数值的数值值的数值的数值的数值的数值的数值的数值的数值,显示了,显示了,显示了,显示了全球的数值的数值的数值的数值的数值的数值的数值的数值,显示了全球的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值,显示了全球的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的数值的计算。