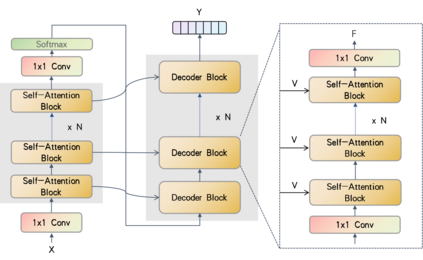
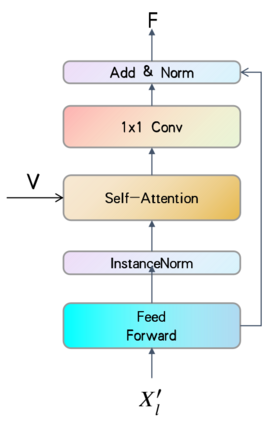
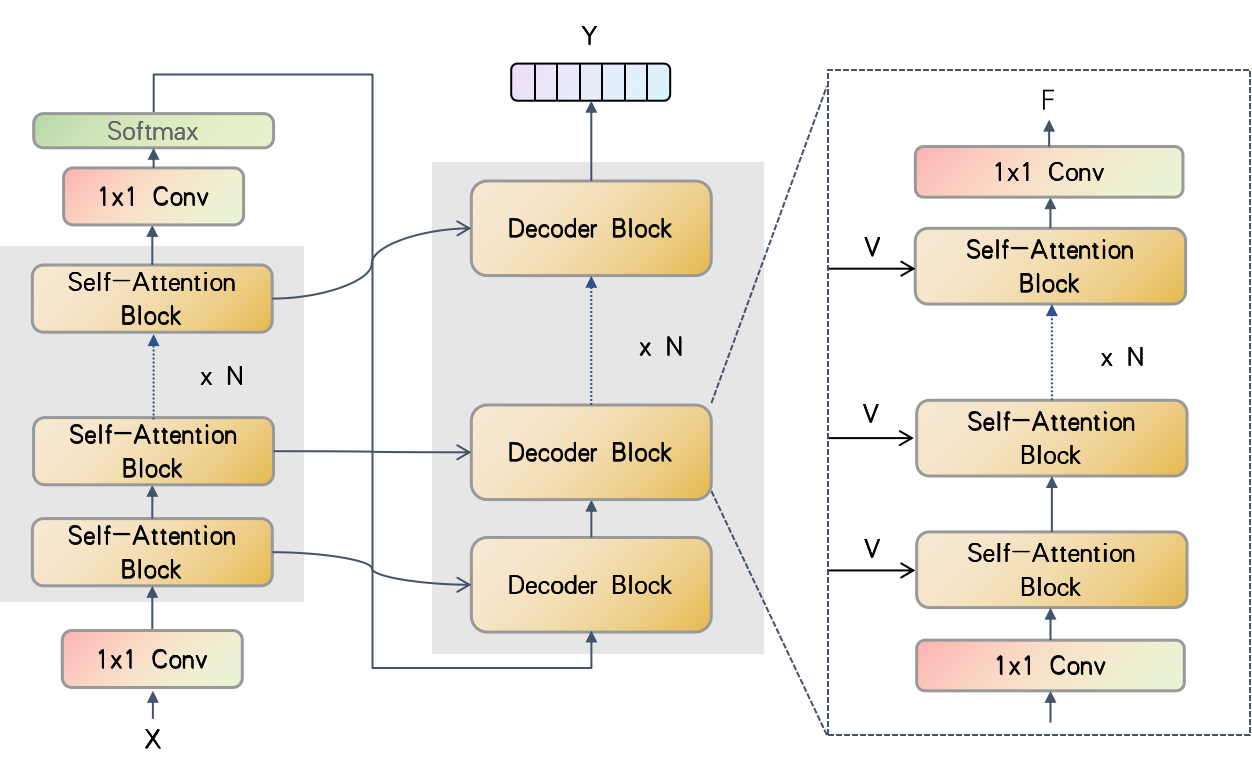
Temporal convolutions have been the paradigm of choice in action segmentation, which enhances long-term receptive fields by increasing convolution layers. However, high layers cause the loss of local information necessary for frame recognition. To solve the above problem, a novel encoder-decoder structure is proposed in this paper, called Cross-Enhancement Transformer. Our approach can be effective learning of temporal structure representation with interactive self-attention mechanism. Concatenated each layer convolutional feature maps in encoder with a set of features in decoder produced via self-attention. Therefore, local and global information are used in a series of frame actions simultaneously. In addition, a new loss function is proposed to enhance the training process that penalizes over-segmentation errors. Experiments show that our framework performs state-of-the-art on three challenging datasets: 50Salads, Georgia Tech Egocentric Activities and the Breakfast dataset.
翻译:时间变迁一直是行动分割的选择范例,通过增加变迁层来增加长期可容纳的场域。 但是,高层导致框架识别所需的本地信息丢失。 为了解决上述问题,本文件建议了一个名为“交叉增强变异器”的新型编码器解码器结构。我们的方法可以是以互动的自我注意机制有效地学习时间结构的表述方式。将每个层的变异特征图汇集在编码器中,并附有通过自省产生的解调器中的一系列特征。因此,在一系列框架行动中同时使用本地和全球信息。此外,还提议了一个新的损失功能,以加强惩罚过度隔离错误的培训过程。实验表明,我们的框架在三个具有挑战性的数据集(50Salads、Georgia技术中心活动和早餐数据集)上表现了现状。