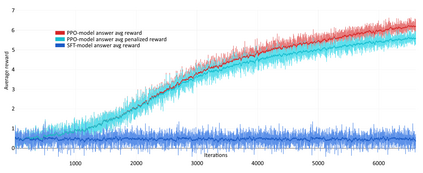
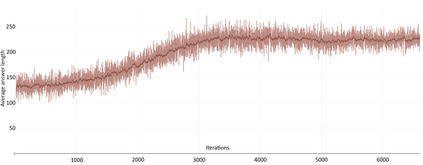
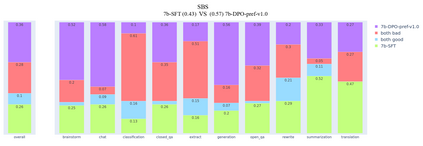
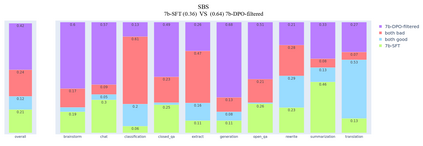
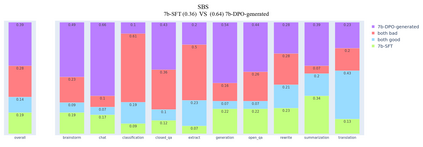
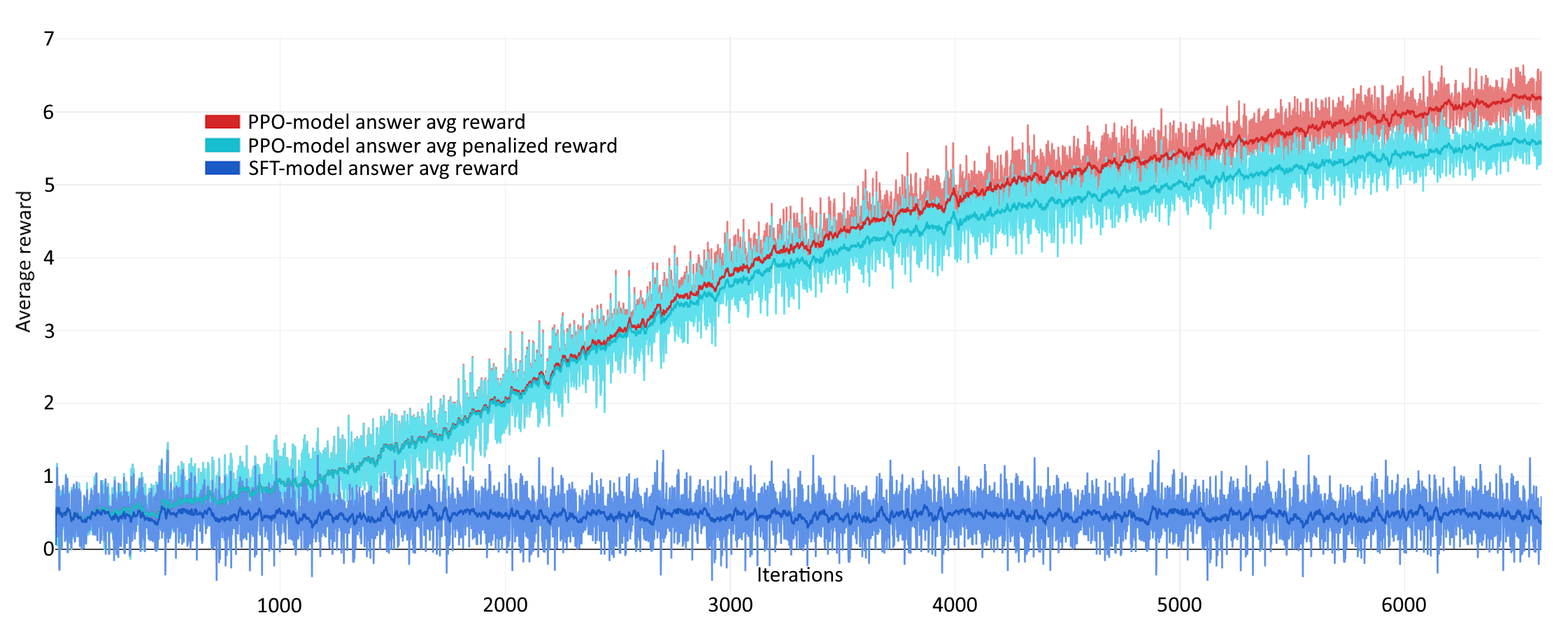
In this article, we investigate the alignment of Large Language Models according to human preferences. We discuss the features of training a Preference Model, which simulates human preferences, and the methods and details we found essential for achieving the best results. We also discuss using Reinforcement Learning to fine-tune Large Language Models and describe the challenges we faced and the ways to overcome them. Additionally, we present our experience with the Direct Preference Optimization method, which enables us to align a Large Language Model with human preferences without creating a separate Preference Model. As our contribution, we introduce the approach for collecting a preference dataset through perplexity filtering, which makes the process of creating such a dataset for a specific Language Model much easier and more cost-effective.
翻译:暂无翻译