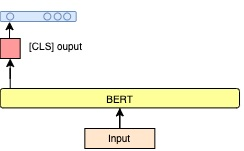
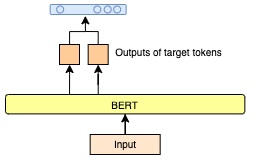
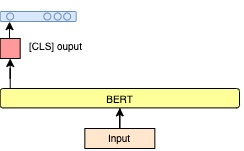
Targeted Sentiment Analysis aims to extract sentiment towards a particular target from a given text. It is a field that is attracting attention due to the increasing accessibility of the Internet, which leads people to generate an enormous amount of data. Sentiment analysis, which in general requires annotated data for training, is a well-researched area for widely studied languages such as English. For low-resource languages such as Turkish, there is a lack of such annotated data. We present an annotated Turkish dataset suitable for targeted sentiment analysis. We also propose BERT-based models with different architectures to accomplish the task of targeted sentiment analysis. The results demonstrate that the proposed models outperform the traditional sentiment analysis models for the targeted sentiment analysis task.
翻译:有针对性的感官分析旨在从特定文本中提取对特定目标的感知,这是一个引起注意的领域,因为互联网的可访问性日益增强,使人们产生大量数据;一般而言,需要附加说明的培训数据的感官分析是广泛研究语言如英语的很好研究领域;对于诸如土耳其语等低资源语言来说,缺乏这种附加说明的数据;我们提出了一个土耳其附加说明的数据集,适合进行有针对性的感官分析;我们还提出了基于BERT的模型,其中含有不同结构,以完成有针对性情绪分析的任务;结果显示,拟议的模型超过了有针对性情绪分析任务的传统情绪分析模型。